
AI in Smart Buildings #3 — Ideation
Oct 16, 2022 | Jagannath Rajagopal | 14 min read
In order to apply a method towards part of your problem, two prior steps are needed. Without understanding your problem structure & its decomposition into sub-problems, you are not going to get very far with this.
Even if you do have a problem structure, resist the urge to dive in and start with methods. This may work for simple problems. But with complex problems like Surveillance in Smart Buildings, you would benefit from first crafting a big-picture flow of tasks for your sub-problems. To do that, you worked backwards from the end goal to the inputs. Here’s what you arrived at & that’s where we’ll start.
Ok, let’s begin. Our goal here is to be illustrative and pedagogical is showcasing how Hero Methods may be applied to complex problems in AI. Actual problems may involve less or more steps based on the scenario.
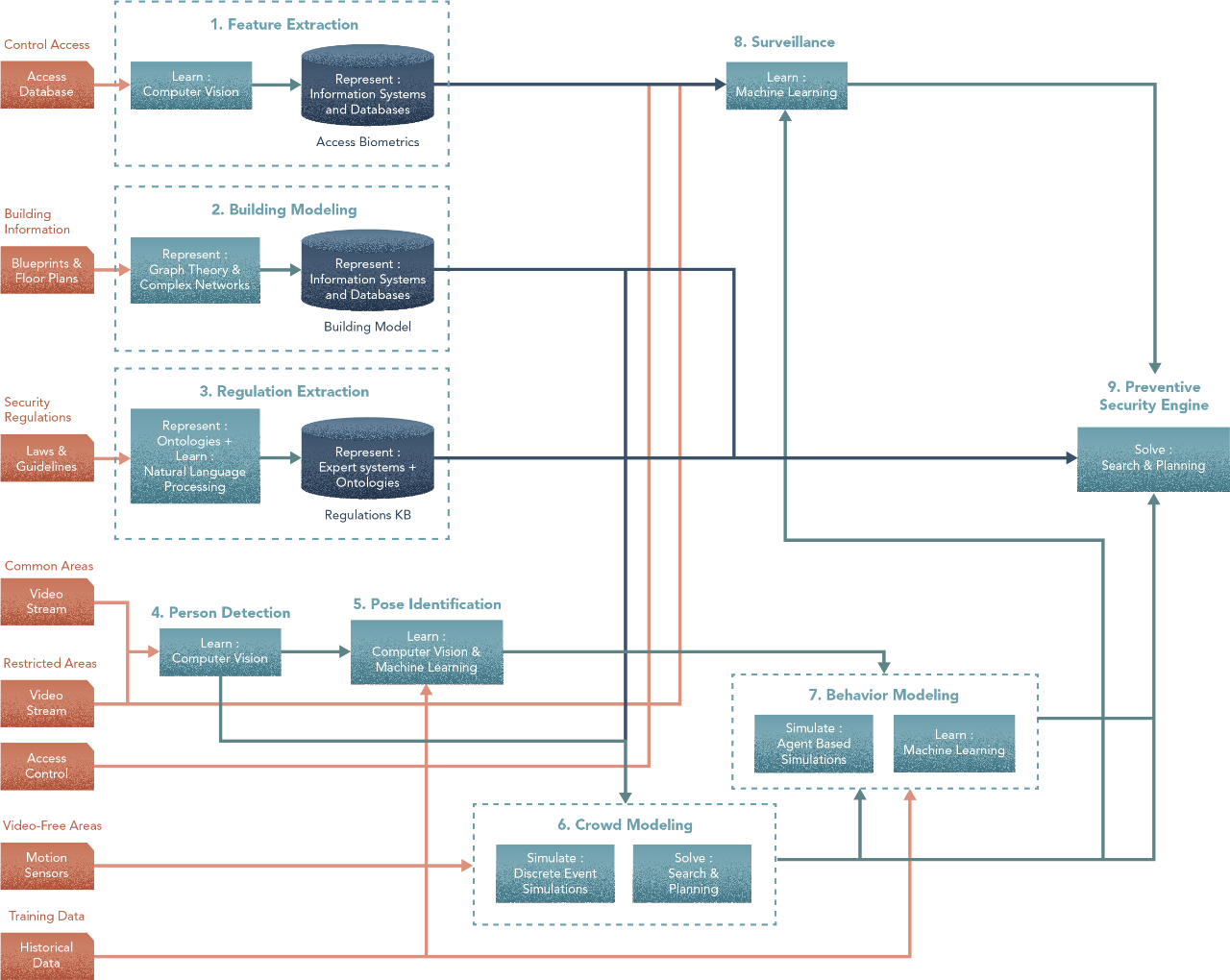
In the design thus far, we see what each step does, but not how. Now, we’ll work forwards from steps 1 to 9 and define each of them.
- - -
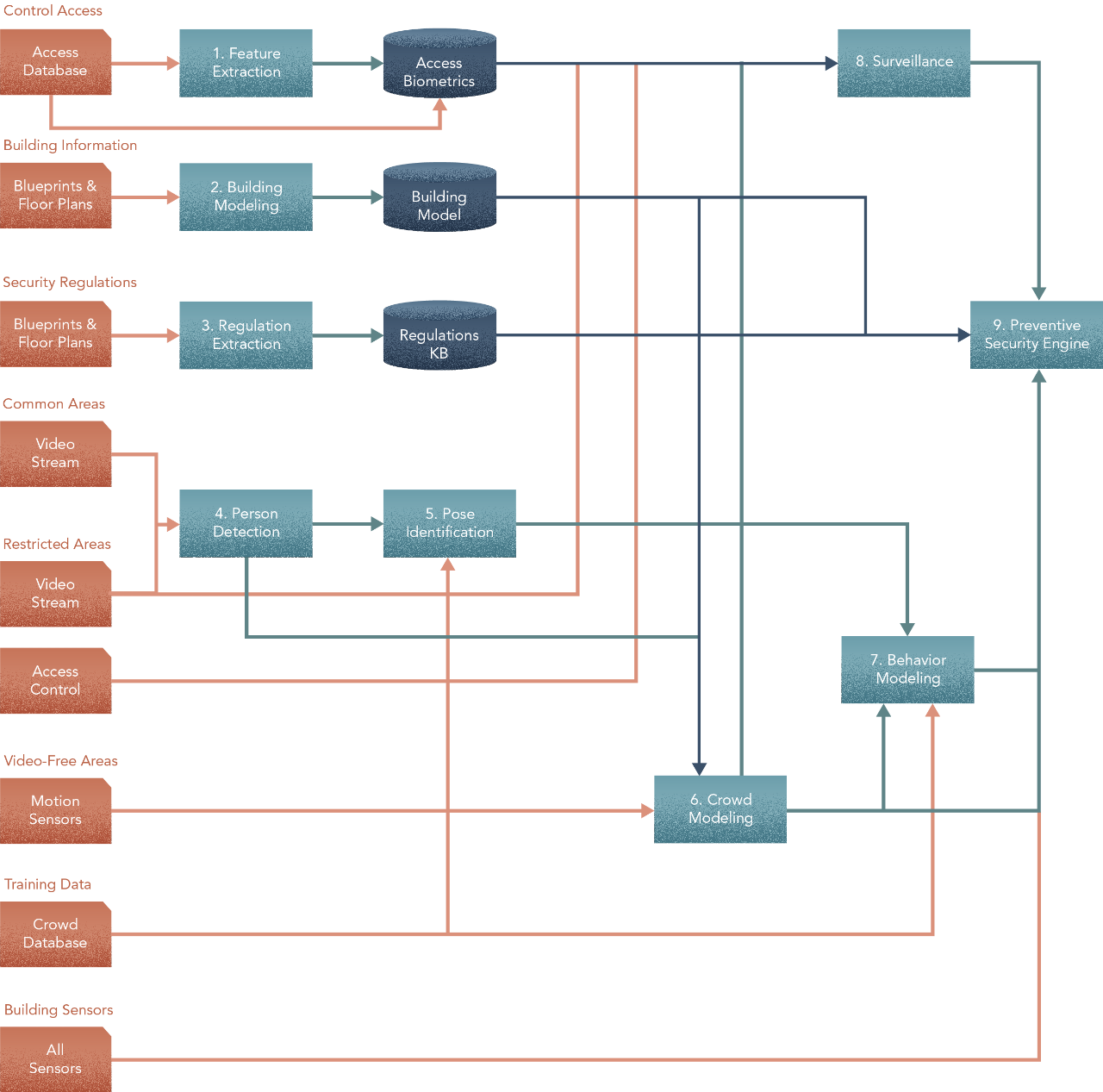
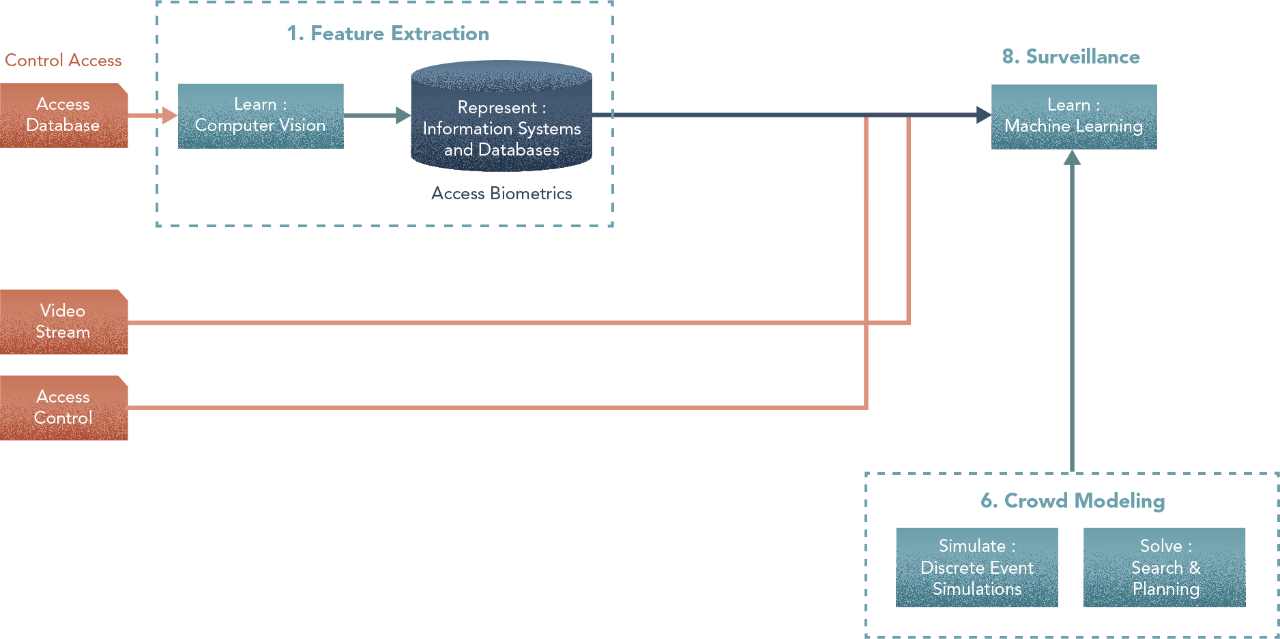
1. Feature Extraction
Central Components: Learner, Representation
From the access control database, we extract morphometric — body/face/shape — features to feed an access biometrics database that stores characteristics of personnel allowed access to restricted areas [Learn: Machine Learning]. We store this information in an analytics-optimized data access system [Represent: Information Systems and Databases]. This step has two parts — a) creating an unsupervised learning problem to obtain the most discriminant features that characterize individuals, and b) storing/retrieving this information for final use, as for instance, a serialization into binary, a parametric raw data representation or even a semantically-oriented one. The objective of this task is to produce the Biometrics Database.
Learner trained with: Images of individuals
Options
- Morphometric: Extract features (sub-areas of images corresponding to eyes, mouth, nose, for instance) by individual based on a morphometric algorithm and then generate a numerical transformation of these and store them into a content-indexed database. For a candidate picture, the process of querying the database is to extract features, to perform the same transformation for the sub-areas, and to find the closest record in the DB to these values.
- Learning-based: Alternatively, we may treat the whole DB of personnel as a dataset of positive cases and along with a DB of other individuals as negative cases, to distinguish people corresponding to the staff from the rest. This approach, nonetheless, may require retraining the model when new people are enrolled, for instance and involves a certain degree of uncertainty.
- For this scenario, the morphometrics approach is a lot more practical than the learning-based one. The challenge with the learning-based approach that makes it almost impractical is that, every time an access control is changed — meaning an employee changes role, joins or leaves — the model will need to be re-trained. Particularly in cases where an employee leaves where the access privileges are revoked, the only way to assure that the model will not give a false positive is that it is fully re-trained. The morphometrics approach on the other hand does not rely on this and so it is a better way to handle this problem.
- - -
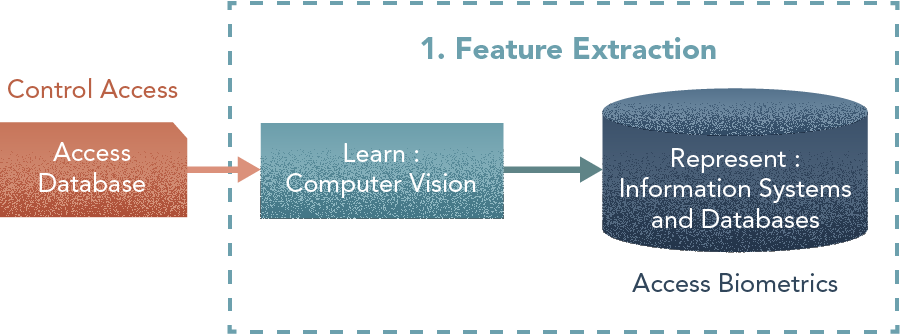
2. Building Model
Central Components: Representation, Solver
From building blueprints or BIM (Building Information Modelling) models, we extract a logical model of the building as a graph [Represent: Graphs Theory & Complex Networks] and as a set of connected volumes and areas. This logical model is physically stored in a graph/spatial database [Represent: Information Systems and Databases]. Information contained in the model is used to produce high-level representations such as exit paths, route density and resilience of the network [Solve: Search and Planning]. The outcome of this task is a Building Model.
Options
- The most basic information includes spaces (rooms/hallways) and their connectivity (doors and staircases). Therefore, the simplest option would be a graph model in which the nodes are spaces and edges represent how they are connected.
- This option can be extended by enriching the information for each node and edge with additional attributes. This can be categorical (such as type/function of the space — restroom, corridor, food court, …) or numerical (volume/surface area, dimensions and sizes, how long it takes to move across the room or cross a connection etc).
- Extending further, information about categories (of rooms or connections) can also be linked to an ontology giving them some additional semantic information related to nodes/edges.
- Finally, additional meta-data can be included using a solver (path-finding, different alternate routes etc) as an option for post-processing the building model output or as pre-processing for Step 6. This additional information may indicate distance to closest exit and which direction, or which are paths in the graph that a given access level allows you to traverse.
I’ve created a LOT of resources on this topic. Here’s my course on Design Thinking for Hero Methods. Here’s my YouTube channel with previews of course videos. Here’s my website; navigate through the courses to find free previews & pdfs.
- - -
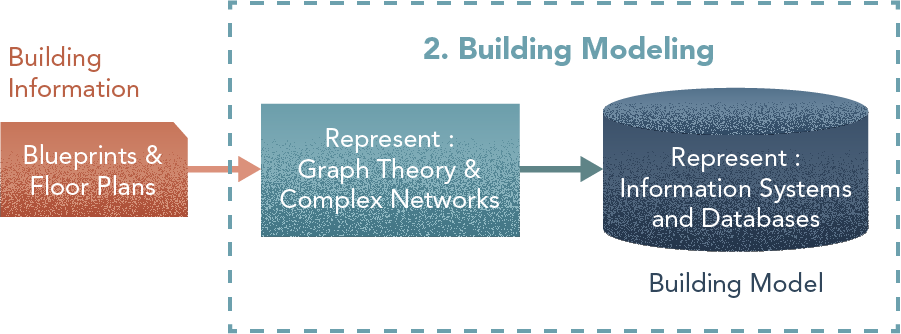
3. Regulation Extraction
Central Component: Learner, Representation (KB)
From existing bodies of regulations and guidelines [Learn: Natural Language Processing], we extract security procedures as rules [Represent: Expert Systems + Ontologies]. We enrich this information with expert knowledge about how to react in the corresponding situations [Represent: Fuzzy Logic]. Regulation preprocessing is in many cases a hybrid process in which several automated tasks assist experts in identifying aspects to model in the system. This depends on the complexity of applied regulations, legal considerations and the availability of experts from whom to obtain complementary information. This task produces a Regulations Knowledge Base.
Learner trained with: Building Regulations Corpora.
Options
- The first alternative is hand-crafting the ontology using traditional expert-system methodologies. This means understanding domain regulations and translating into concepts, rules, and relationships.
- Alternatively, we may use an NLP based approach for automatic extraction of regulations. This approach could be more interesting if these regulations vary significantly or if we are designing a solution to be deployed in different buildings around the globe and we have to deal with different sets of regulations on a regular basis.
- Finally, a solution may need a combination of both, having an NLP model extract structures in a regulation and then an expert post-process these results to speed-up the task of creating the ontology.

- - -
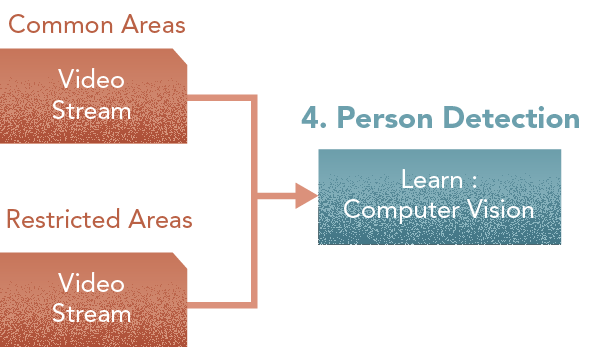
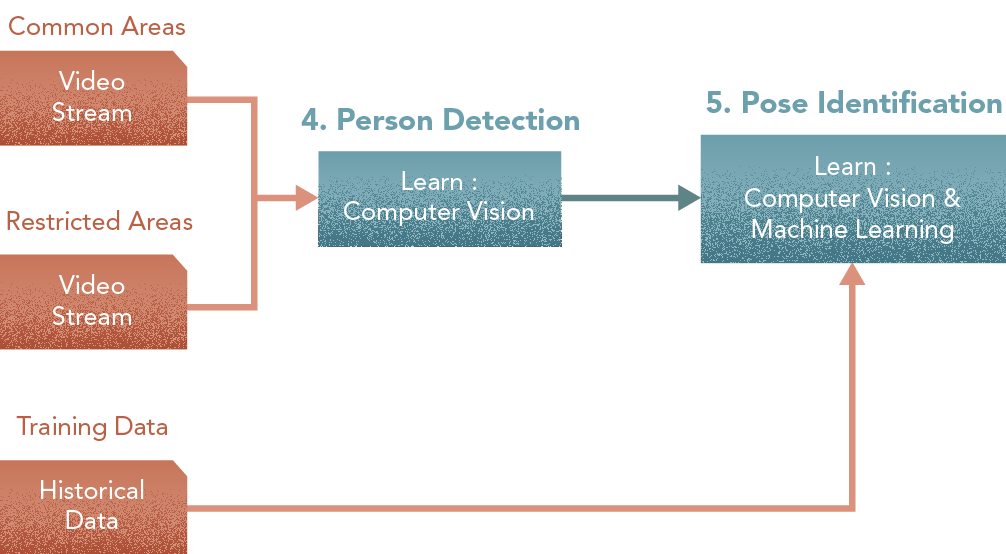
4. Person Detector
Central Component: Learner
This module processes video feeds from the common and restricted areas to perform identification of moving objects with the objective of detecting people moving in the scene. This will be done for both common and restricted areas [Learn: Computer Vision]
Trained with: Historical footage
Options
- The simplest option is to use computer vision to trigger signals when a significant change happens in the image, or to even detect the group of pixels that are changing to track an object in a scene.
- This option is sometimes very limiting if you want to identify the nature of the object moving in the scene (ex., is it a person, a dog, a baby stroller). This can be done by using some specific algorithms that detect simple components (mostly shapes), or by training a learning model to recognize a person. You may be able to find pre-trained state-of-the-art object-recognition models and adapt them to your problem, thus reducing your effort needed in training.
- - -
5. Pose Identifier
Central Component: Learner
Among the people tracked by the person-detector, this module detects those performing actions that have been classified as a potential crime [Learn: Computer Vision & Machine Learning].
Trained with: Historical footage.
Options
- Opposite to step 4, here we utilize ML or DL. One approach is the identification of joints — detecting knees, elbows, hips and other major joints, and drawing a basic skeleton structure (a type of 12-to-20-segment wireframe representation) of the person detected. Sub-steps include (a) detecting joints, (b) estimating skeleton, and © characterizing pose
- An alternative to this approach is to directly train a DL algorithm with video sequences and the tag of the pose. This requires more (labeled) data for training and tries to solve the problem holistically.
- - -
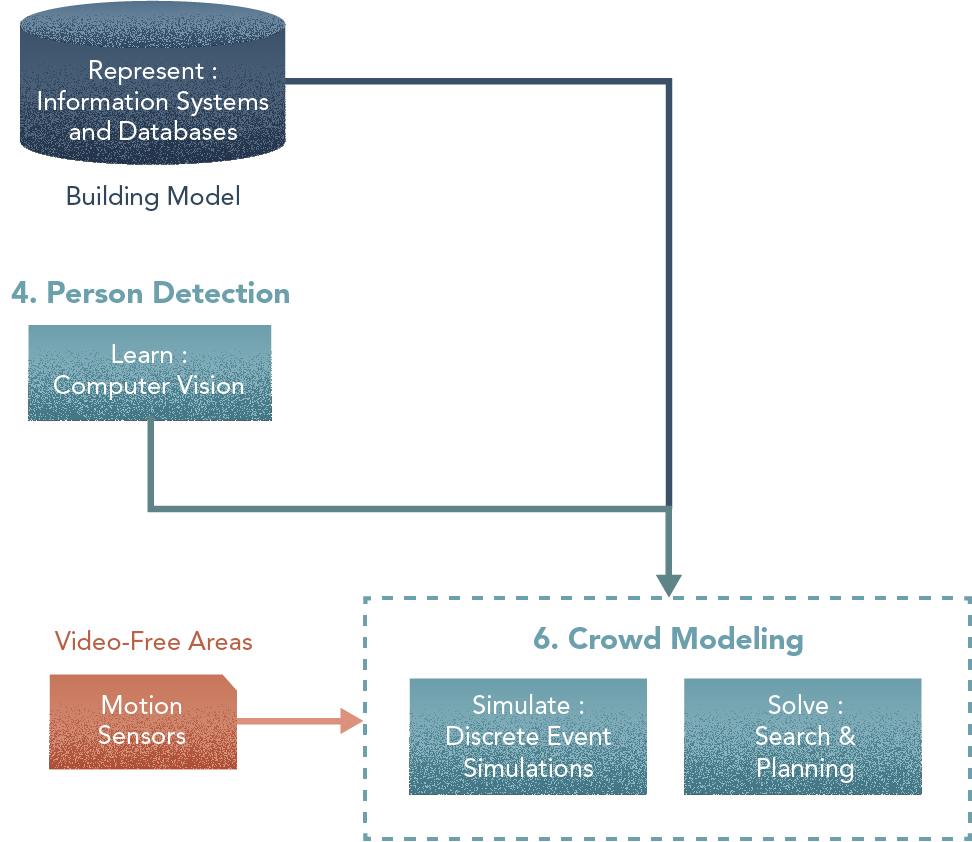
6. Crowd Model
Central components: Simulator, Solver
This module integrates person detector output, sensor input from camera-free areas, and the building model, into a Crowd Model. [Solve: Search and Planning] + [Simulate: Discrete Event Simulations]. This step is a good example of synergies that result from combining different approaches. Here, the static or aggregate representation provided by a graph model is insufficient to analyse the problem, and so a simulation is needed as the primary element in modelling a building crowd. In turn, the simulation needs a graph-based representation to model the context of the problem (as from Step 2), a solver in pathfinding for solving navigation problems and a planner to link simple actions into execution plans (actions taken in order to accomplish certain objectives)
Simulation: Discrete Event Simulation
Solver trained with: Video footage of crowds (macroscopic validation).
Options
There are two alternatives to simulate the crowd, depending on the amount of information we want to use from the model.
- For either alternative, a solver may be used to chart pathways through the building. Depending on the size and complexity of the building, the number of theoretical pathways can be very large. If a mall has 100 stores, there are 100 x 99 ways in which one person can visit 2 stores. Even if one determines realistic paths, or attempts to simplify the problem by discretizing the space [ex., pathways to a store, not within a store], the number of routes may still be high. If it is possible to do manually, a solver may not be needed. Then for a simulation, a solver may be used to determine the relevant options out of the existing ones. If in an agent-based simulation of a mall, a particular individual only needs to visit 3 specific stores, the solver can then determine the possible routes that individual could take, as a pre-processing step. Also, a solver may be used to react to situations within a mall — like a large crowd, or a closed corridor, or a broken elevator etc.
- The simpler option is a discrete-event simulation (mostly a queue system) that identifies the number of people per node of the graph (spaces in the building). There is a given task the people perform in each node — like walking, shopping, looking at the store displayed items, going to the restroom etc — and the probability or plan to transit to the next node. This approach is good to estimate the total number of people per area of the building and other statistics about the flow of people. These simulations work at the individual level but the representation of the world (e.g. the building) is very simplified and does not consider necessary aspects of the problem such as space geometry, density etc except in a very simplified way.
- The alternative is to use agent-based simulations. This option improves the solution in two ways (a) it is easier to deal with actual geometrical constraints such as collisions (too many people using a escalator, for instance) and (b) it aims to embed a plan and an objective to each individual instead of a random walk (e.g., buy a t-shirt, eat in the cafeteria, catch a movie, and then leave). It doesn’t mean that the event-driven simulations do not allow that level of agency or planning of the components. Discrete-event simulations focus more on the processes and less on the actors, while agent-based simulations focus on the intentions and objectives of an agent.
- There are hybrid simulation approaches, mostly because discrete-event simulation is mostly a way to implement a simulation process and agent-based is a methodology to design the actors. Both approaches can be easily combined.
- If we choose the Discrete Event Simulation way, we will need to model Behaviour-Design-Intent as pre-processing for Step 7.
- - -
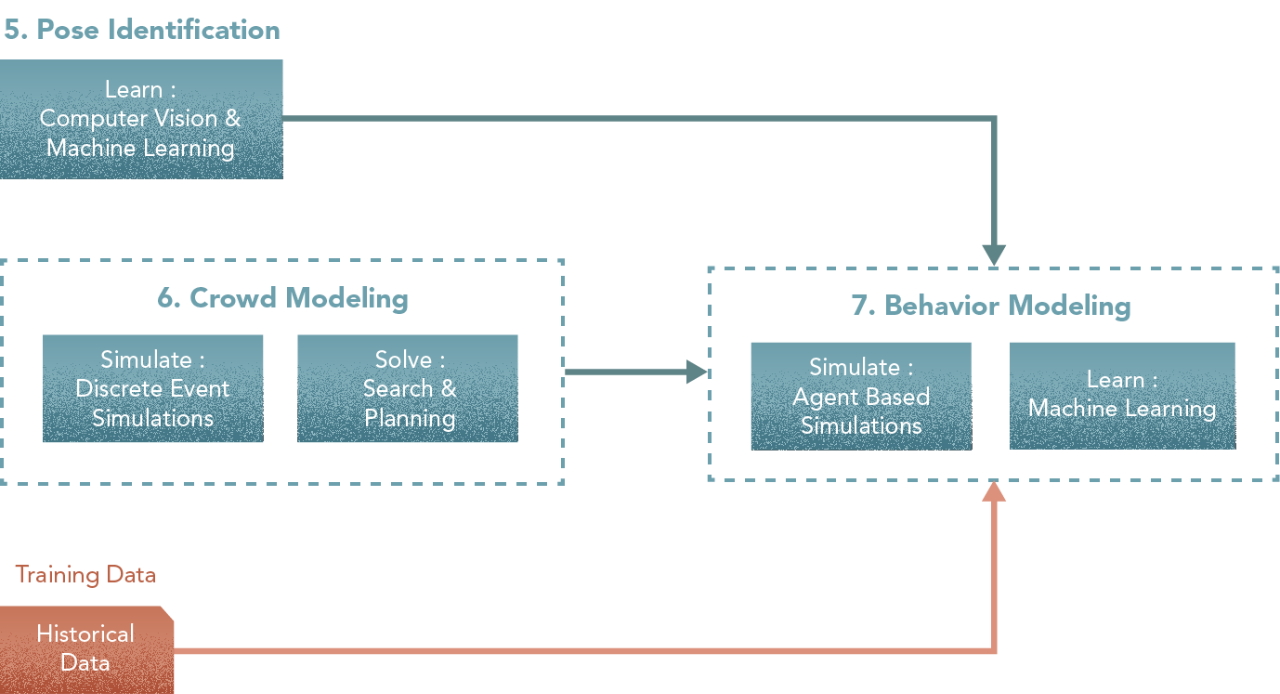
7. Behaviour Model
Central components: Simulator, Learner.
This module uses the output from both the crowd model and the pose identifier to model complex suspicious actions like roaming, movement patterns, person-person interaction, person-object interaction, area characteristics etc [Simulate: Agent-based Modelling] and to classify them accordingly [Learn: Machine Learning]. The core of this activity is to learn how to identify actions that are potentially suspicious when combined together. Such actions typically involve movement and interaction, and training a learning algorithm to effectively learn from a database of past situations is very difficult.
Simulation: Model movement, interaction, behaviour to produce synthetic data set. Use pose identifier outcomes.
Learner Trained with: Synthetic data set, & crowd model outcomes.
Options
- Options for this step are closely linked to those in step 6. If we opted for an agent-based implementation, crowd behaviour can be modelled as an extension of agent-planning. The easiest approach is to have a basic perception model and a simple internal state representation that allows the agents to switch between plans depending on some fixed rules (e.g. I’m tired so I am going to stop shopping, find a bench, and eat something or leave the mall).
- A more advanced model would consider the interpretation of the environment. There are computational cognitive models that implement perception and elicitation processes. If the simulation deals with, for instance, emergency simulations such as a fire or people evacuating the building in a hurry, these models better capture these situations.
- Regardless of simulation approach, a learning model is needed to characterize the type of crowd behaviour.
- A problem in the more advanced behavioural models is how to calibrate them. An approach is to use basic ML (simple regressors) to assign values to behaviour parameters based on a database of actual historical and synthetic reference cases.
- - -
8. Surveillance
Central component: Learner.
Using biometrics from the Access database and outcomes from the crowd model, this module recognizes faces [Learn: Computer Vision + Machine Learning] of people moving within restricted areas based on access control permissions. It combines different inputs — data from the access control systems, as well as video feeds from restricted areas. While Step 1 deals with Feature Extraction, here we are primarily concerned with surveillance. In an Access Control mechanism, the task deals with frontal images in a perfectly illuminated set-up with no occlusion or perspective issues. For Access Control, either the individual is identified based on their unique biometrics or not, and there shall be no (or close to zero) error tolerance. For surveillance, input video sequences of an individual are recorded from different angles and different light conditions in motion; it becomes necessary to deal with noise and uncertainty as well as correct for perspective and occlusion. This makes Surveillance a more complex problem and one in which there are a wide range of expectations in regards to its accuracy. The Surveillance process starts getting hints about the identity of a person as the video sequences unfold and work towards determining the probability of the person being a trespasser. Furthermore, the gathered aggregated evidence helps the human in the control center determine what and when a response action is triggered. Here, this step deeply depends on the outcomes and outputs from Feature Extraction. The work already done by the former may assist the latter.
Trained with: An independent database of subjects, biometrics from Access Database, outcomes from the crowd model, as well as video feeds of areas in the building.
Options
- As mentioned, the alternatives for this step are closely related to step 1. In the case of implementing an ML-based solution in step 1, we need to extend the training database with images coming from video sequences in different illumination conditions and perspectives. It is unlikely to solve the problem as a single supervised ML problem. It is common to decompose into several preprocessing steps for segmenting objects, and performing image transformations to correct contrast, illumination, perspective, occlusion, etc. Also, because of the issue with access control changes, you may have to train/retrain models either by individual or by access area.
- Alternatively, it is possible to treat the Surveillance problem as an extension of the Access Control process by Extracting morphometric features generated by the Surveillance process. The idea then is to extract not only features but also several internal parameters (the transformations performed to get features from sub-areas of pictures such as the eye, the nose or the mouth etc) that can be good inputs for the training of this component. The problem may be formulated so that learning is still a part of it. The input would be raw video sequence from the surveillance cameras & crowd model outcomes. The task is to segment faces in video, correct for perspective and occlusion (and so on), extract facial feature vectors, and match to morphometric vectors from the biometrics database. Machine learning models, especially deep neural networks, are famous for not requiring hand-crafting of features and filters in image recognition so the first parts — segmenting, correcting and extracting — could potentially be set up as a data-driven one. The matching process would then utilize a simple distance measure to determine which morphometric vector the extracted facial feature vector is closest to. The output would be the combination — Name, Trespasser Yes/No, Degree of Certainty
- - -
9. Preventive Security Engine
Central component: Solver.
This module integrates the outcomes from the behaviour model and the facial recognizer to model, manage and operate different alarm levels. This model uses the Regulations KB to perform automatic preventive measures, like locking priority locations when detecting a potential intruder in restricted areas. If there are other kinds of safety alarms (e.g., fire alarm) and authorized people in those locations [Solve: Logical Programming] at the same time, it notifies the security personnel and suggests fast access routes while preventing intruders from escaping [Solve: Search and Planning]. This final step is interesting because it not only integrates outcomes of many of the previous steps but also shows how top-level decision-making components combine information learned from raw data with expert knowledge. The Security Engine may also be modelled as a Learner or a Simulator.
Trained with: No training per se. Testing and validation is scenario based and done by experts.
Options
- The core of the system can be a rule-based engine. These are either implemented in logic programming languages (e.g., Prolog or Lisp) or use an intermediate programming format to describe rules. This engine shall be able to propose a sequence of actions to deal with a particular situation based on the current state of the system (occupation of the building).
- Sometimes, these engines use extended implementations based on partial order planning. This extends the basic rule-based systems to deal with a problem by proposing a sequence of actions (several of which can be performed in alternative orders) to find the objective state of the system.
- If the Building Model (step 2) does not consider the aspects of pathfinding, this step has to implement them. In essence, it has to provide a mechanism to establish optimal (feasible) routes for people to take as part of the mechanism to model movement.
- - -
In the next article, we’ll replace methods with techniques. At the moment, this is still too high-level; we’ll drill into each of the above to select techniques and lead to being able to write a spec for your developers to prototype. The rubber is approaching the road bit by bit!
At Kado, combining methods into an architecture to solve complex problems is what we do. Here’s the why — cuz this is amazing!
This is how we see the world
Machine Learning is King, but of narrow territory. Hero Methods do things that ML cannot. Taken together, not only do they help solve complex problems, they also lay the doorway to AI.
Get in touch
-
Milton, ON L9T 6T2, Canada
-
help@kado.ai
-
+1 416 619 0517
Copyright © 2026
Super!
An email is on it's way.
Super!
An email is on it's way.
Created with
