
AI in Smart Buildings #2 — The Big Picture
Oct 14, 2022 | Jagannath Rajagopal | 8 min read
In the first article of the Smart Building series, we introduced the Smart Building problem. Here’s the summary.
- - -
Say a smart building designer wants to model intentions in different floors for surveillance Though the problem body mentions HVAC, we focus just on security for the specific example. The idea is to simulate activity on entire floors in an effort to manage security risks. It is expected this may potentially result in savings of $2 million every year.
Hierarchy
There are three different perspectives that can be modelled
- Spatial — Whole building, location (floor, parking lot etc), sub-location (wing, room cafeteria etc), or by camera.
- Security/Access — Could be as simple as common areas vs restricted. Depending on the building, there could be many levels of security. There may also be user input to regulate access to certain areas (like apartments).
- Function — Surveillance vs access control vs scenario analysis. We choose this perspective as this allows the best richness from an illustration standpoint; each of the levels has a different set of inputs/features that it works with. Surveillance is about cameras while access control may be about access cards/biometrics.
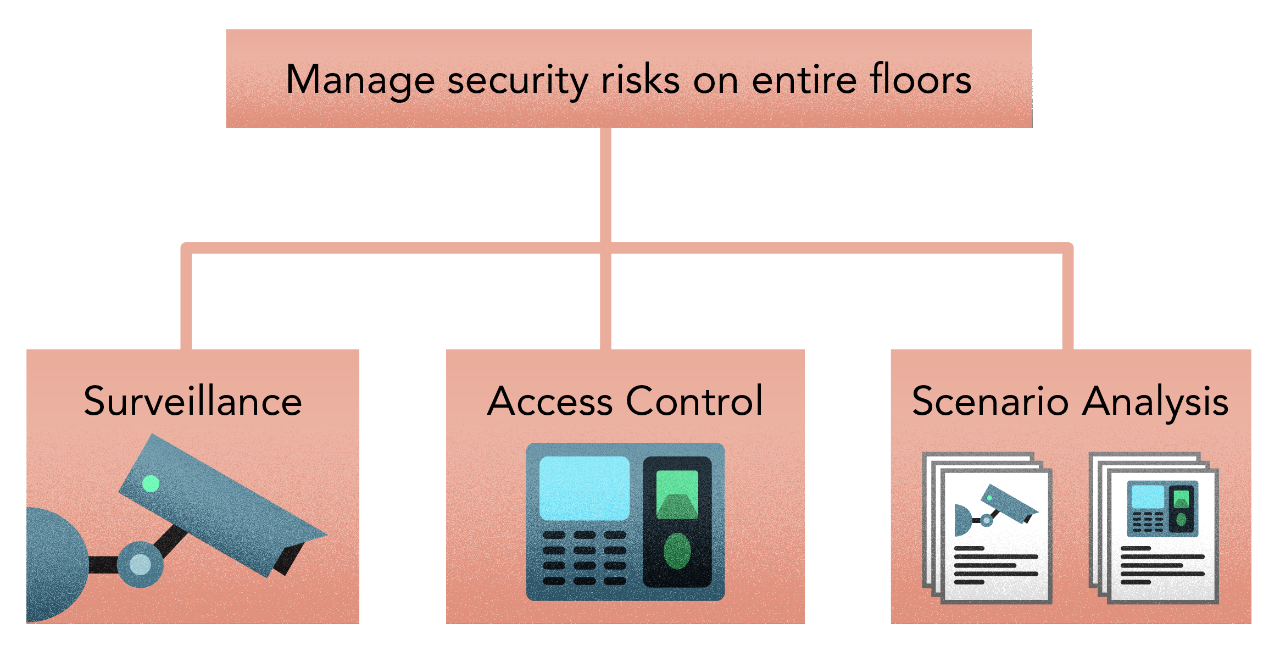
Inter-relationships
There are two kinds: input data and model.
- Cameras and other sensors complement each other to provide a full view of the target being surveilled. Each input has a partial view of the target and multiple inputs may need to be combined to get the full view. Alternately, for access control, smart cards, biometrics and facial recognition may be combined together to increase accuracy of identifying people and providing access to restricted areas. While entry through access points needs to be perfect, a certain degree of error may be tolerated in facial recognition on intruders (you need to know someone is intruding as opposed to who it is).
- Incident analysis in or operation of a security engine requires multiple components interacting with each other — a representation of rules/regulations, models of crowd behaviour, and/or other components like those that manage safety protocols.
Pipeline
- Survey common areas including corridors, restrooms, food courts, shopping, and parking.
- Survey restricted areas such as offices, management areas, warehouses, etc.
- Prevent shoplifting, burglary (cars in parking lots), pickpocketing, or other illegal activities.
- Enforce security in restricted areas by detecting unauthorized persons in these areas.
- Where video surveillance is restricted (e.g., toilets, locker rooms), manage with alternate indirect sensor surveillance.
- Comply with existing regulations, be unbiased to race/gender, and follow safety and security laws and guidelines.
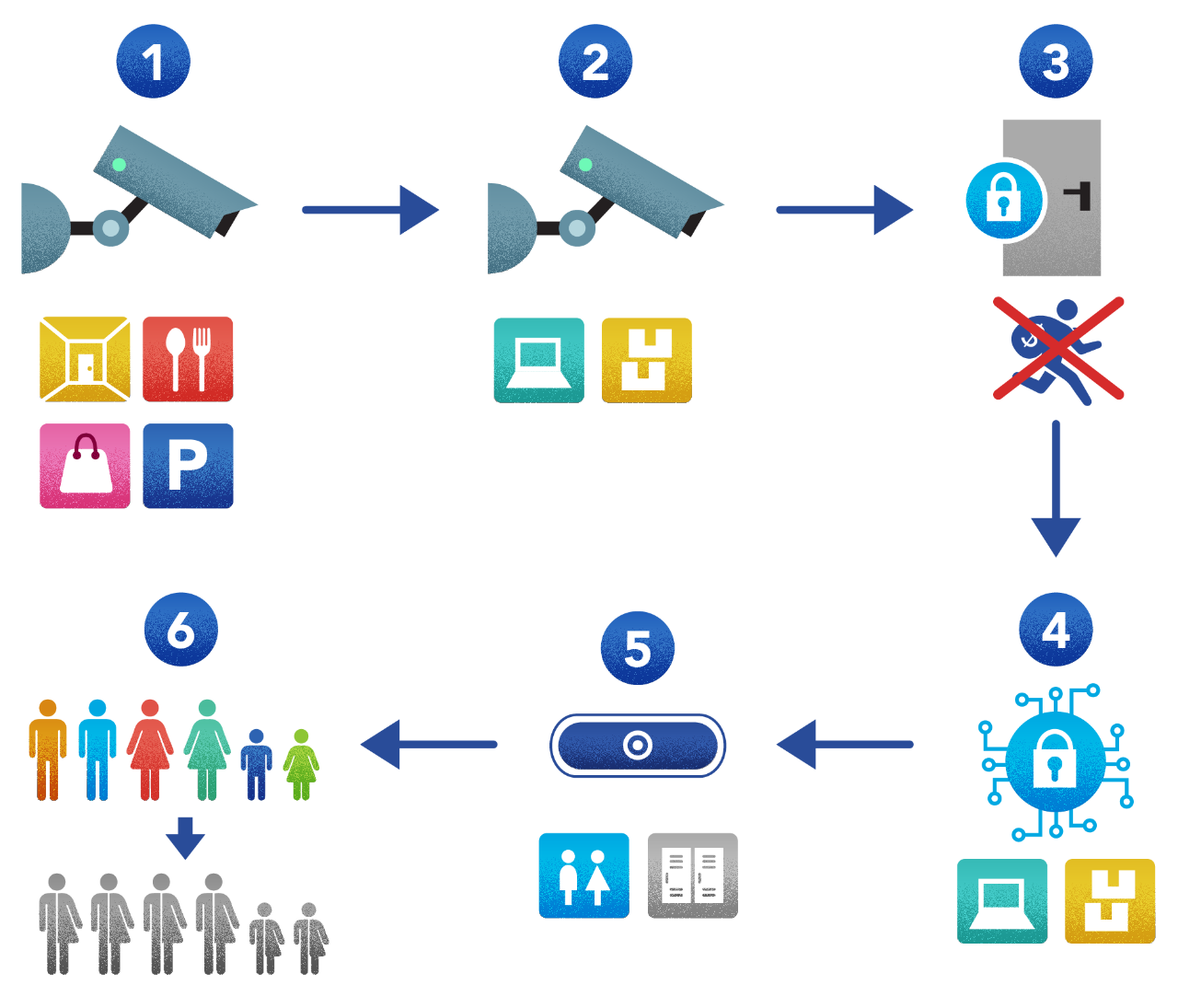
The pipeline steps above list all sub-problems that need solving. To do the solving, we’ll first imagine the solution as a set of functional steps. For each functional step, we’ll need 1 or more methods, and for each methods, we’ll need 1 or more techniques.
Of course, the mapping could also go the other way — 2 or more functional steps could be solved by a method, and 2 or more methods by a single technique. For our problem, there are situations where the former applies. With the 2 surveillance sub-problems — common vs restricted — there is a single set of methods that solve them.
Let’s begin. Our goal here is to be illustrative and pedagogical is showcasing how Hero Methods may be applied to complex problems in AI. Actual problems may involve less or more steps based on the scenario.
- - -
We’ll follow this approach to specify and develop the design for Surveillance in Smart Buildings. In this Smart Building Problem, learning is ubiquitous, as seen in Steps 1,3, 4, 5, 7, & 8 below. Learning is a big part of this problem as is the fact that the problem largely depends on and is driven by data. It is also a good example of how learning can be combined with other Hero methods to form architectures that solve complex problems.
Insights
There are several hypotheses we’ve made based on what we know about the space. All of them need testing.
Biometrics
Biometric models of faces — models that represent facial features/parts (mouth, eyes, nose etc) — make it easier for a facial recognizer to be trained successfully to a high degree of precision. In that sense, they act as a data pre-processing step. Biometric models make for an existing representation of the human face, and in this sense, the facial recognizer does not need to work as hard to build and recognize a human face from scratch each time. This preprocessing step helps in simplifying the facial recognizer and hence making it smaller and easier to deploy on the edge. For these reasons, we are prototyping with a biometric model as part of our initial hypothesis
Complexity
Modelling a smart building is characterized by two dimensions. Complexity is one; the bigger the building and the more purposes it serves, the more complex the model is. With size and function, the number of paths, the types of agents etc increase along with their interaction. However, we can choose the level at which we model this. For example, a store can be modelled as a single node and a buyer can have simple interactions like “enter, purchase, exit”. This way, there isn’t too much emphasis on what happens inside a store. This may not be relevant when looking at the building as a whole.
Crowds
In order to model crowd behaviour, we’ll first need to model crowds separately. The security engine will regardless need both.
It is possible to enhance a crowd model with a model of individual attributes, making individuals behave differently depending on these characteristics: Facial Biometrics & Individual poses
Learning crowds from data — video, images, voice etc — is not an effective approach to behaviour modelling, although it could be helpful for validation purposes.
It is not a good idea to model crowd behaviour as a monolithic black box. Possible scenarios may be missed. Further, it’s very difficult to troubleshoot during the learning process.
I’ve created a LOT of resources on this topic. Here’s my course on Design Thinking for Hero Methods. Here’s my YouTube channel with previews of course videos. Here’s my website; navigate through the courses to find free previews & pdfs.
- - -
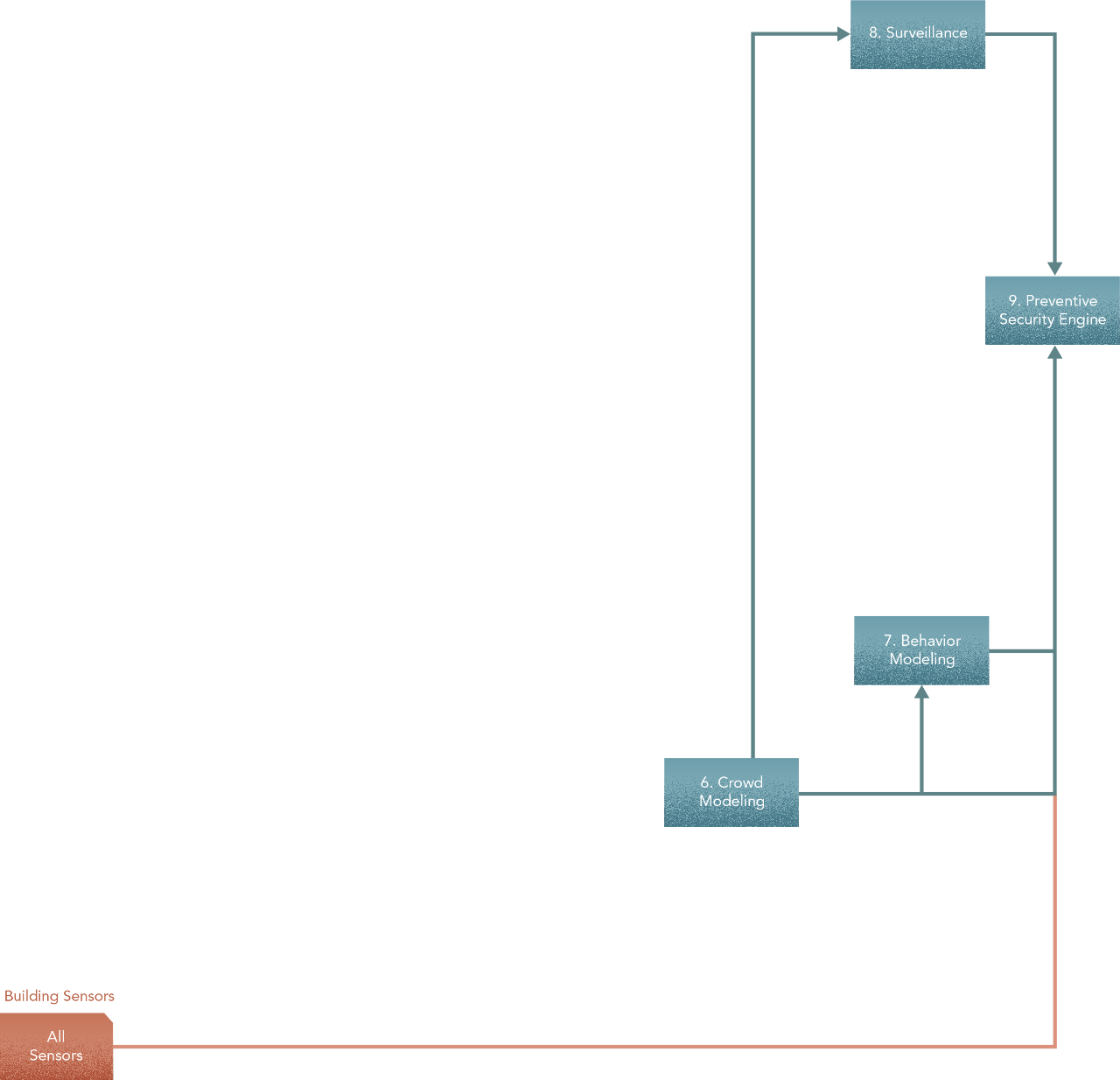
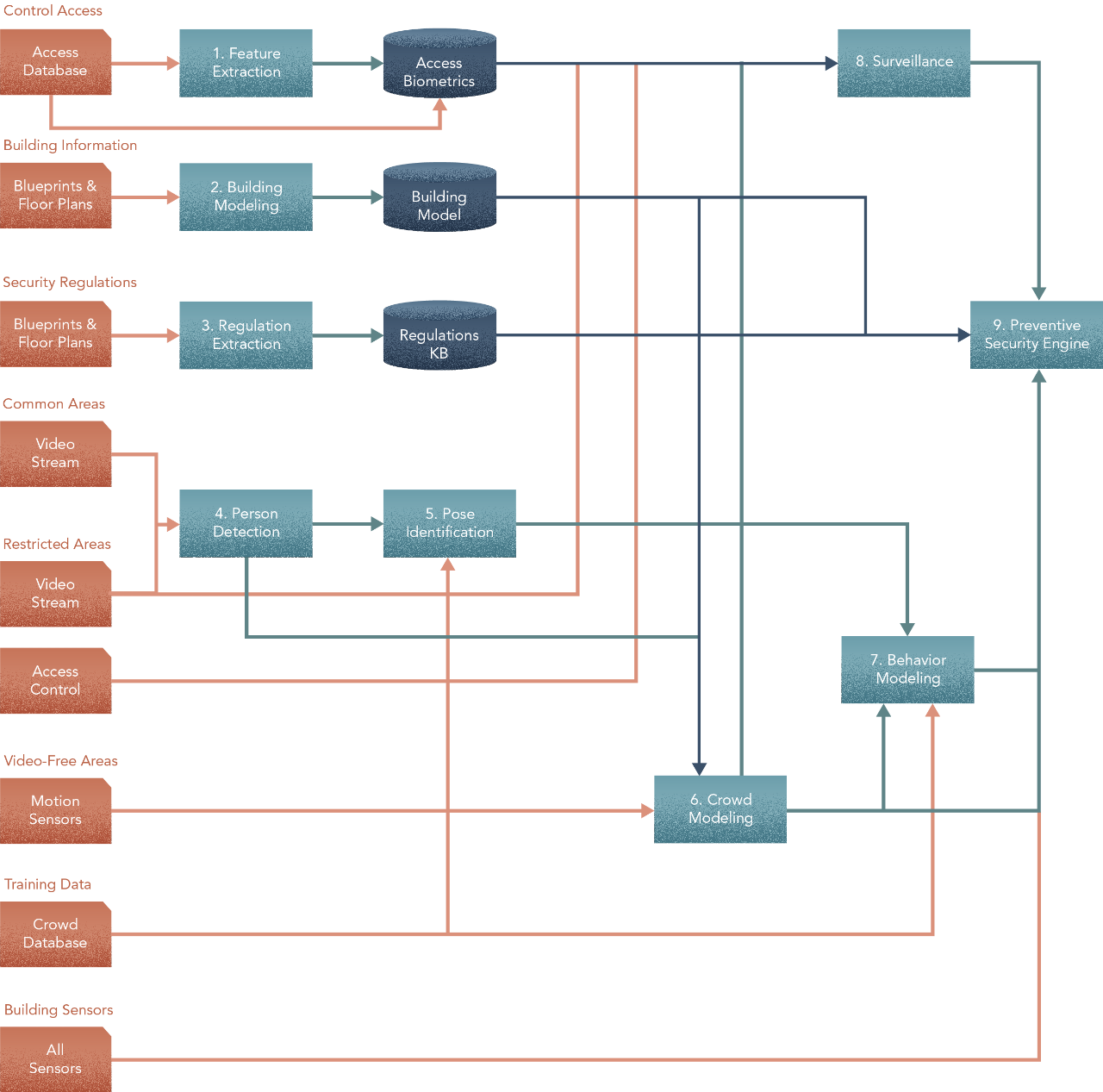
The end goal in design is the security engine. To architect this, we start here — at the end. The security engine in our scenario has two main jobs each of which addresses a specific question/problem -
- Surveillance. We’ll need a facial recognition model of everyone who has access to the building, and which parts each person has access to. This model will then feed the security engine with real-time information about whether someone is in an area he/she is not supposed to be in.
- Incident analysis and response. “Incident analysis in or operation of a security engine requires multiple components interacting with each other — a representation of rules/regulations, models of crowd behaviour, and/or other components like those that manage safety protocols.” In order to build the security engine, we need a couple of parts — a) Representation of rules/regulations, and b) Models of crowd behaviour. To do this, first we’ll need a model of crowds in a building. A behaviour model would use its output to know what a crowd is.
The security engine would combine the two logically, along with building sensor input, to infer what a crowd should and shouldn’t be doing. The security engine may also use the crowd model’s output in order to interpret the behaviour model.
Thus far, our high level design looks like this -
To build a crowd model for a building, we’ll need two parts — a model of the building, and a person detector. Building models — the digital twins of physical buildings — are usually created and stored in the Building Information Management (BIM) system. They use blueprints and floor-prints as input. We saw before in Section 3 — Crowds from Individuals and Section 2 — Hierarchy about scaling an individual — in this case the person detector — to model a crowd. That’s what we’ll need to do to obtain the crowd model. Just like the facial recognizer, the person detector will use video feeds from common and restricted areas, as well as motion-sensor data in video-free areas.
Rules and regulations are usually documented and made available to their intended audience in Natural Language — for our purposes, we assume these are already available in a reasonable digitized format. We’ll need a way to represent laws and guidelines from legal sources in some form of formal knowledge representation. This knowledge representation will then serve as the source of rules to the Security engine. Finally, the BIM system also provides an inventory of spaces and connectivity to the Security engine.
With these, the design now becomes -
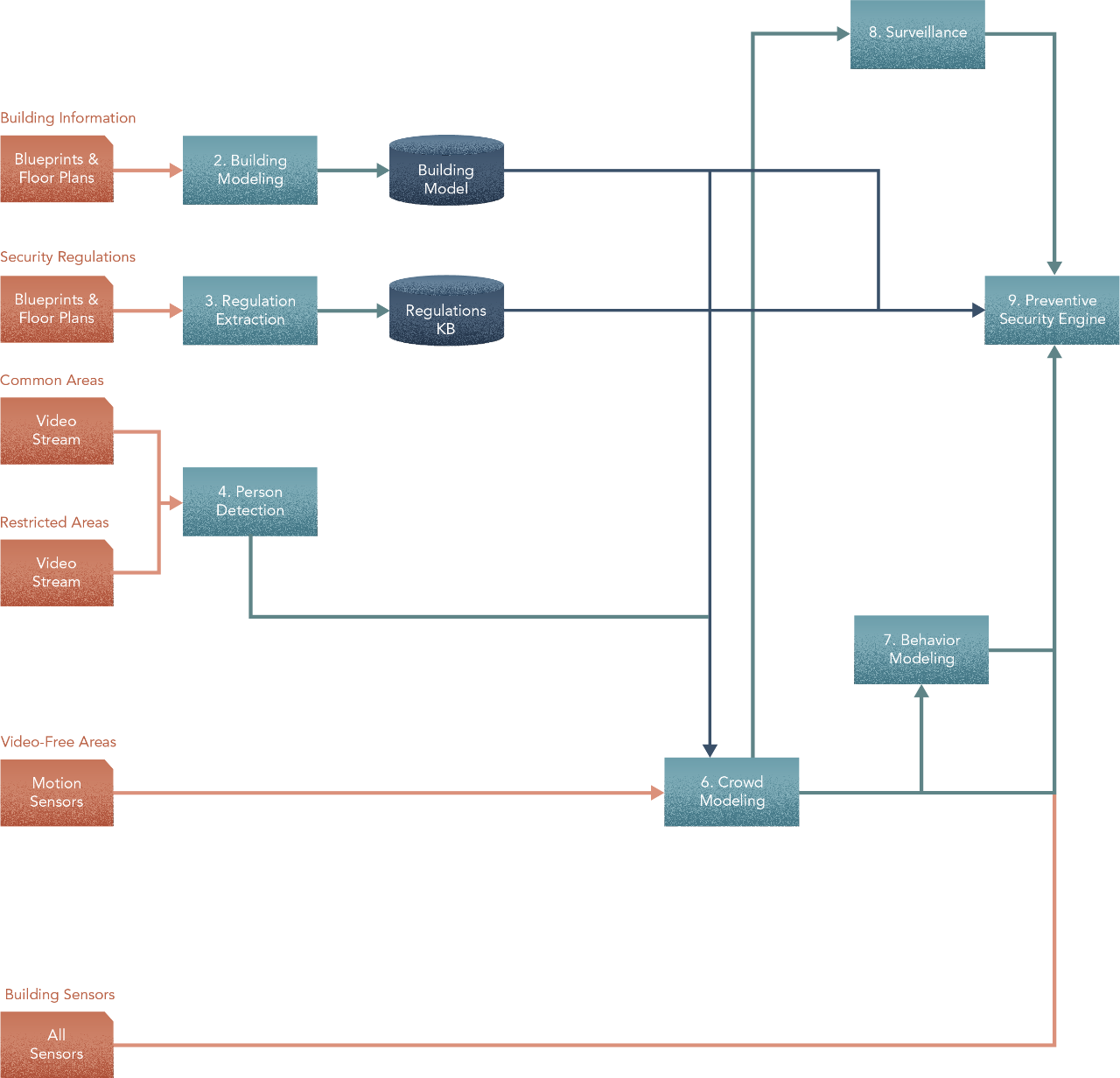
The surveillance model will need video feeds from all areas — common or restricted — to do its job. Without feeds, there is no knowing who’s where at any point in time. In order to recognize people, it will also need biometric models of faces. These may be stored in an access biometrics database, which we’ll need to build. To model biometrics, we’ll need to get access control information — pictures of people’s faces along with where they have access. This is usually stored in a security and access control system that facilities and buildings usually have. Note that the prep step of using biometrics to help with the facial recognition model is something you can test. Vision models tend to be black boxes; having a biometrics prep step increases trust in the system when it does work and makes for more effective troubleshooting when it doesn’t. Strictly speaking however, state-of-the-art vision models of faces do not require biometrics so this is one area where judgment may be applied. As we’ll see later, there may be drawbacks in a pure learning based approach to model faces. It may make sense to compare options for performance, complexity, reliability and costs.
If there are many people in a restricted area, the surveillance model will need to single out those that have do not have access. It will need the output from the crowd model to make sense of the group.
In addition to the crowd model, you’ll also need a pose identifier along with historical data, to model behaviour. Obtaining good quality historical data on movement and interaction may be difficult. However, this may be remedied by simulating a synthetic data set. The pose identifier will need the output of the person detector to do its thing.
With these, the design now looks like this -
In the next article, we’ll drill into each of the above process steps for some understanding on how to select methods for them.
At Kado, combining methods into an architecture to solve complex problems is what we do. Here’s the why — cuz this is compelling!
This is how we see the world
Machine Learning is King, but of narrow territory. Hero Methods do things that ML cannot. Taken together, not only do they help solve complex problems, they also lay the doorway to AI.
Get in touch
-
Milton, ON L9T 6T2, Canada
-
help@kado.ai
-
+1 416 619 0517
Copyright © 2026
Super!
An email is on it's way.
Super!
An email is on it's way.
Created with
