
Methods in AI: The Magnificent Seven — Represent
Oct 14, 2022 | Jagannath Rajagopal | 8 min read
In my first article, I introduced the idea of Hero Methods, which form the foundation for building pathways towards AI. There are 7 methods -
- Learn
- Optimize
- Simulate
- Represent
- Solve
- Deal with Uncertainty
- Compute
6 (Statistics) & 7 (Computer Science) are obviously whole domains in themselves; we are only concerned about those aspects that deal with 1–5, like High Performance Computing.
- - -
It’s a sunny day. You’ve got the top down on your favorite Coastal Highway. Your speedometer is busted, but your car still rides beautifully. You can’t help but notice that you cross a kilometre marker approximately every 20 seconds. Let’s say you were to “collect data” on this by timing each kilometre marker crossing. Based on this, you obtain a piece of information — your speed is 180 kilometres per hour. (111MPH for those of you stateside). This lets you know that you are going 80kph over the highway speed limit! It’s probably unwise to keep at it and hit the breaks before you have your license suspended.
This fun little metaphor may lead you to think of a continuum of what one knows based on how much meaning the information carries. Take this: Data becomes information, Information becomes Knowledge, Knowledge becomes Wisdom. Understanding this as a human thought process this makes sense especially with regard to interactions amongst people. It helps to think of this continuum as a pyramid.
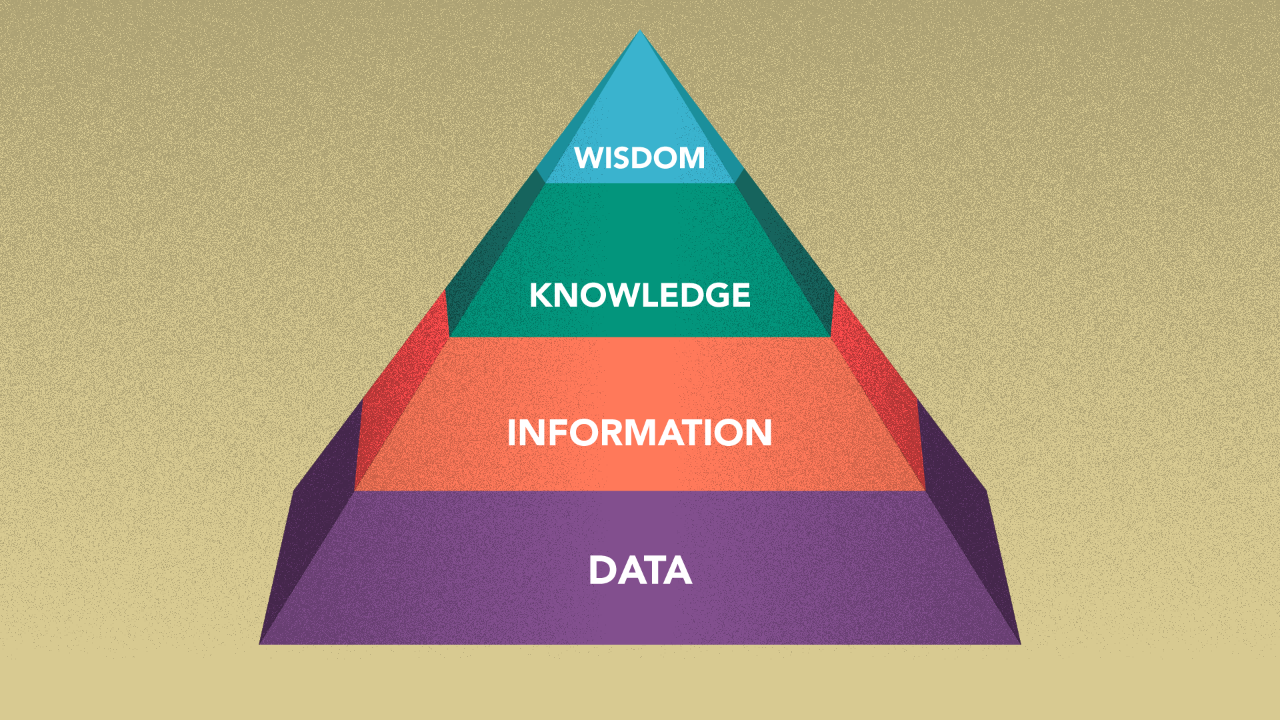
At the base of the pyramid, we have Data — Information. While raw data may have some structure, data sets by themselves don’t usually carry any formal definition of meaning. Raw data is also missing how the data elements are related to one another and furthermore to other concepts and ideas in this world.
Information on the other hand is organized data. There is some level of inherent structure and certain levels of relationship between data elements. Information may also be obtained by manipulating data based on formulae, a guideline, or via a process.
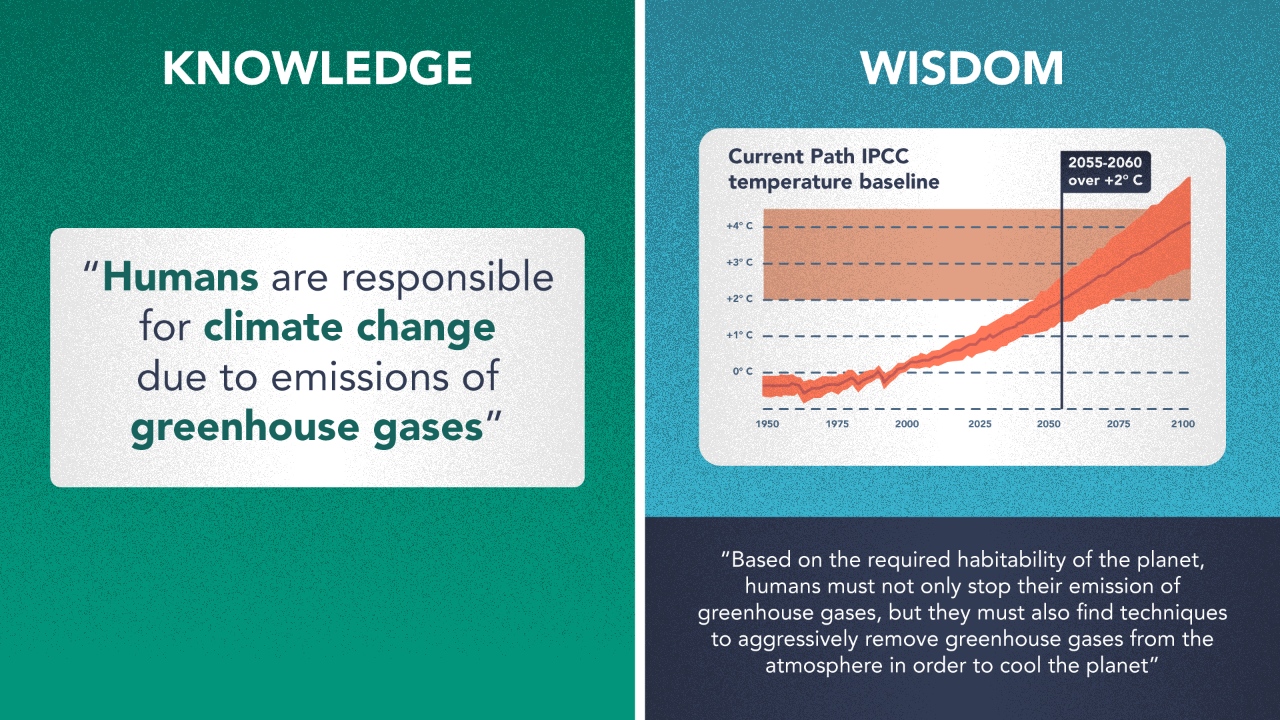
For a weather system, raw data that could include dates and times, temperatures, air quality, and different types of particulate matter. This data when organized becomes information, and suggests that the planet has warmed 1 degree celsius since 1750 and this trend is increasing rapidly.
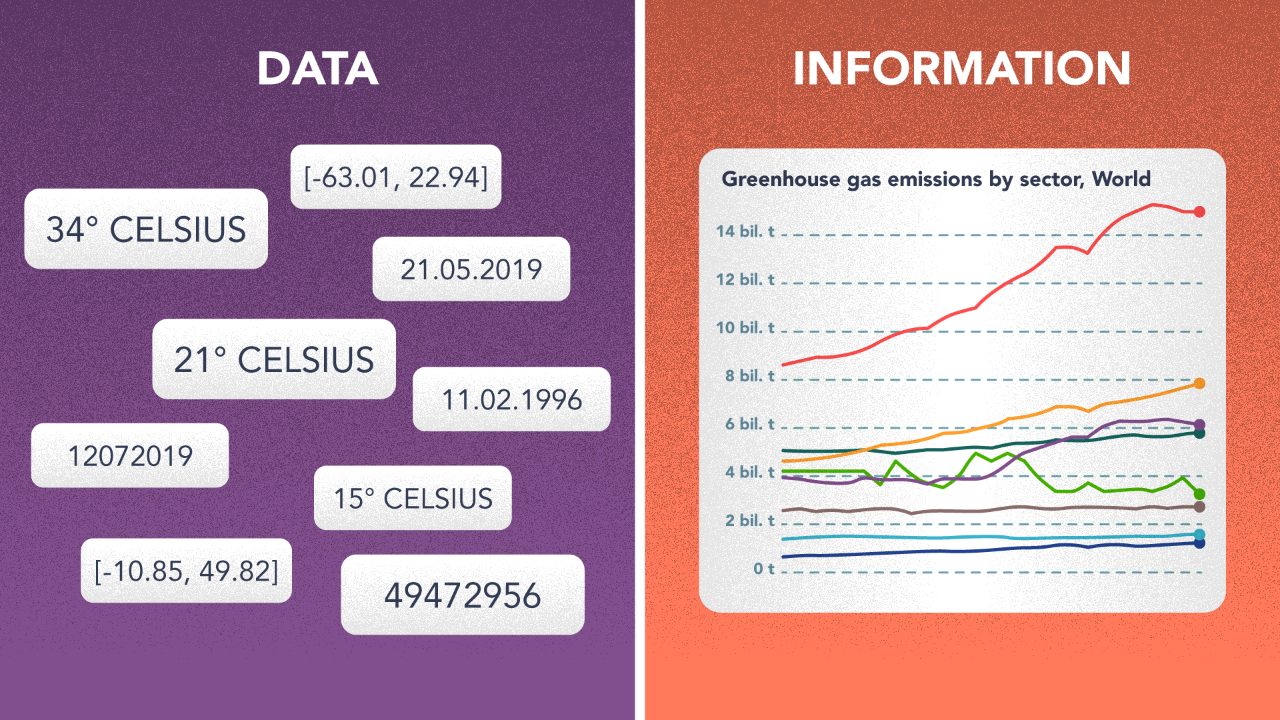
As you scale the pyramid more meaning is gained. Knowledge represents things you know based on a piece of information. This includes things that you know as the result of information and things that relate to that information. Wisdom relates to the soundness of action, thought and decision making in the presence of knowledge.
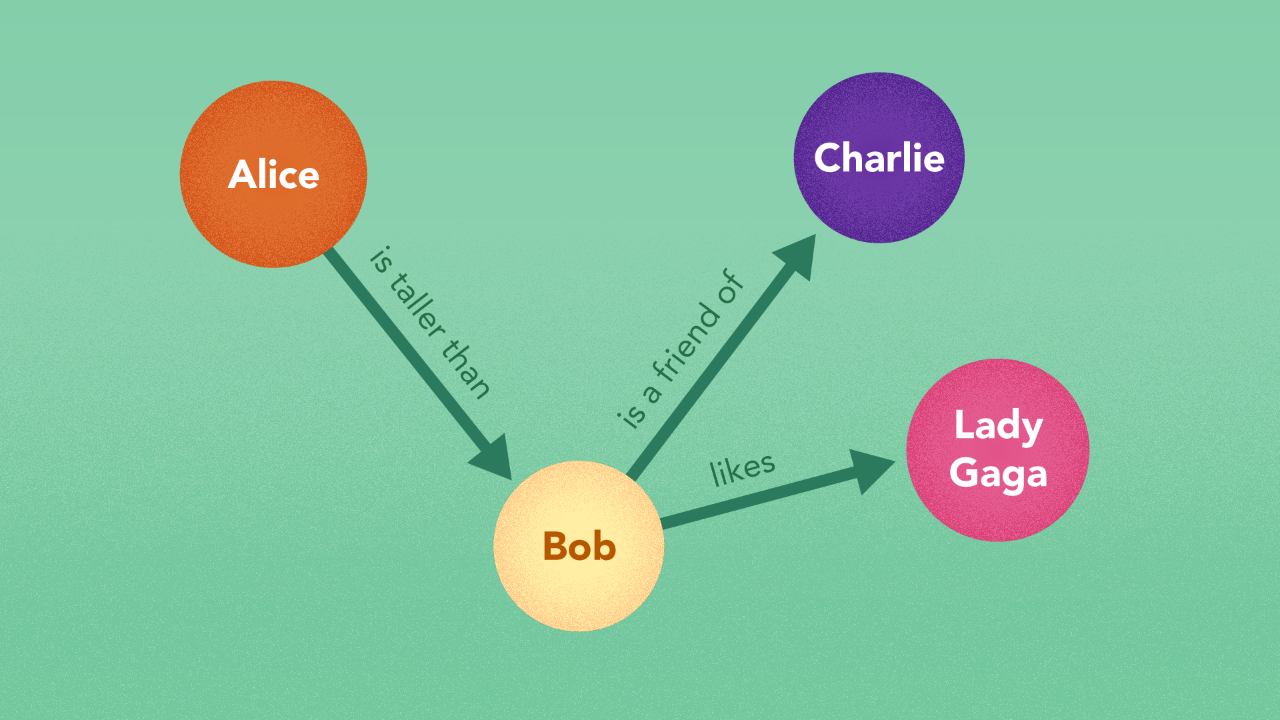
In computing you must represent meaning in a formal way before it can be taught and defined to the system. The lower end of the continuum i.e. data and information are represented in the format of files and databases. Files carry data with some tagging, while databases (including relational databases) can be designed to carry information. Databases can model very complex pieces of information but they sacrifice efficiency in the process. On the other hand graphs can also be used to store information. Practically, graphs tend to carry richer information than databases because they have the ability o efficiently model open worlds and interrelationships between different things.
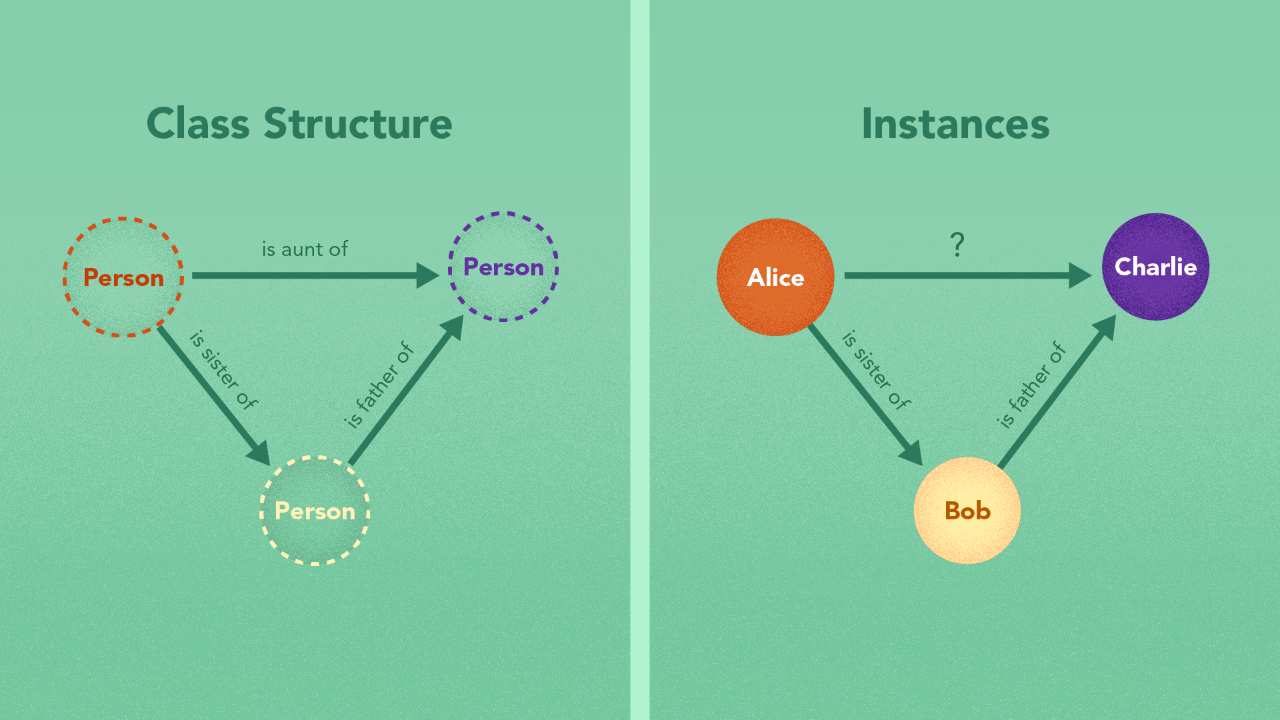
One way to build relationships between two disparate instances is to form facts. A fact connects two things — a subject and an object — by a predicate relationship. “Alice is taller than Bob” connects “Alice” and “Bob” by the predicate “is taller than”. “Bob” may then be connected to “Lady Gaga” by “likes”. “Bob” may be connected to “Charlie” by “is a friend of”. This kind of structure that lets you connect multiple instances with others using predicates is known as a graph or a network where the subject and object are nodes and the predicate is represented as an edge.
In order to efficiently represent and manage knowledge, you need to utilize an ontology. This is a system that lets you define relationships between types and classes of things. Classes can also have subclasses classes or be part of other classes. This way, the ideas, concepts and categories in a world can be efficiently represented.
An ontology allows for knowledge representation in terms of concepts and categories, and their relationships.The rule “the sister of the father of a person is an aunt to that person” may be set up as a three way relationship between 3 categories of people — the subject person, the father, and the father’s sister. We do this so that the instances that fall under a category/concept can inherit the relationships to other concepts and ideas automatically without having to be redefined. By defining two facts — “Bob is Charlie’s Father” and “Alice is Bob’s sister”, we can infer the third fact — “Alice is Charlie’s aunt”. Such a structure that contains relationships between instances, classes and concepts, is referred to as an ontology.
Ontologies lie at the heart of expert systems, a traditional AI method — aka GOFAI (Good Old-fashioned AI) — used to “simulate” knowledge of a domain expert. They capture know-how in a formal manner so that it may be generalized and applied to problems in a domain. Another popular method is case-based reasoning; where a problem is modelled like a former case given their similarities.”
Wisdom on the other hand is very difficult to model because it is hard to formalize. As such, there are no formats for a machine to store and manage wisdom. Practically speaking, there really isn’t a branch of computer science that deals with “wisdom-management”.
I’ve created a LOT of resources on this topic. Here’s my course on Design Thinking for Hero Methods. Here’s my YouTube channel with previews of course videos. Here’s my website; navigate through the courses to find free previews & pdfs.
- - -
Once represented, how do you capture and derive meaning from wisdom, to support decisions and actions? Non-hero systems use the lower parts of the data pyramid as input to deal with problems in a formulaic manner. Much of the intelligence and meaning behind these problems is captured as rules and specifications. Since the underlying data is not smart and meaningful the system must to be. As you move up the pyramid, the structures become cleverer. They carry more meaning, and are more intelligent. This means a non-hero system built on top of them can afford to be less intelligent, since some of the heavy lifting is already done in the representation.
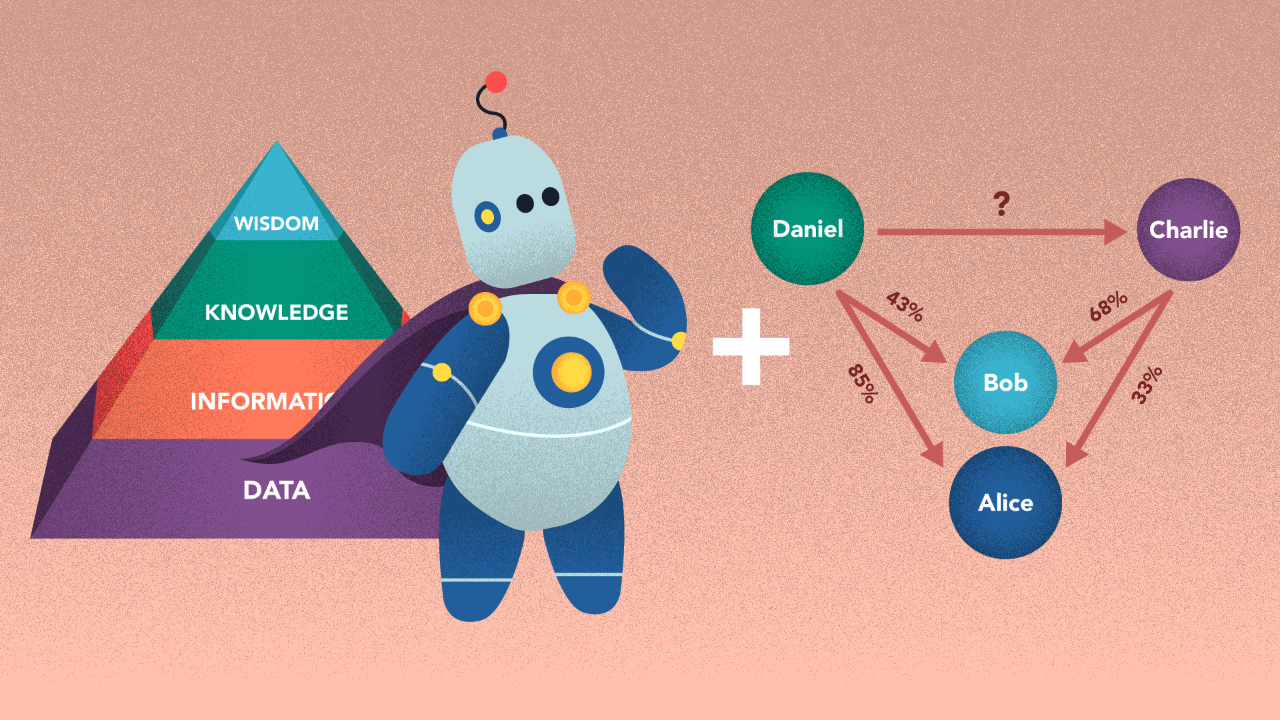
Still it begs the question, how do you determine when to utilize a more intelligent hero system in conjunction with your representation?
If your world is deterministic in nature, knowledge about the world may be captured in a graph or ontology. Graphs and complex networks contain inherent information about their structure which can be thought of as “info about info”. This knowledge may be sussed out by a machine to learn something about what the graph is modelling. Ontologies on the other hand are a formal representation of deterministic facts, concepts, classes and individuals, and their relationships.
When attempting to make the most of either form (graphs or ontologies), non-Hero methods will not do them justice. Instead of a non-Hero method, you may want to use Hero models that are built on top of graphs or ontologies, along with logical reasoning to accomplish your desired task. Hero methods may be combined with graphs or ontologies in different ways — to be better define which parts of the ontology are relevant to the problem, having an enriched input, etc. Logical reasoning helps the machine make deductions based on what’s already defined.
But what if the world is probabilistic in nature? When this is the case, Hero methods are perfect.
The lower the level in the pyramid, the more a Hero method is needed. Learning models take raw data as input, and suss out relationships between variables that can’t be explained as rules. Probabilistic Graphical models encode relationships between random variables, and can be considered to be similar to an ontology for scenarios with stochastic data. Simulation and optimization models can work on either form, as can problem solving methods. In this sense, hero methods are similar to their non-hero counterparts, but they can do much more than them.
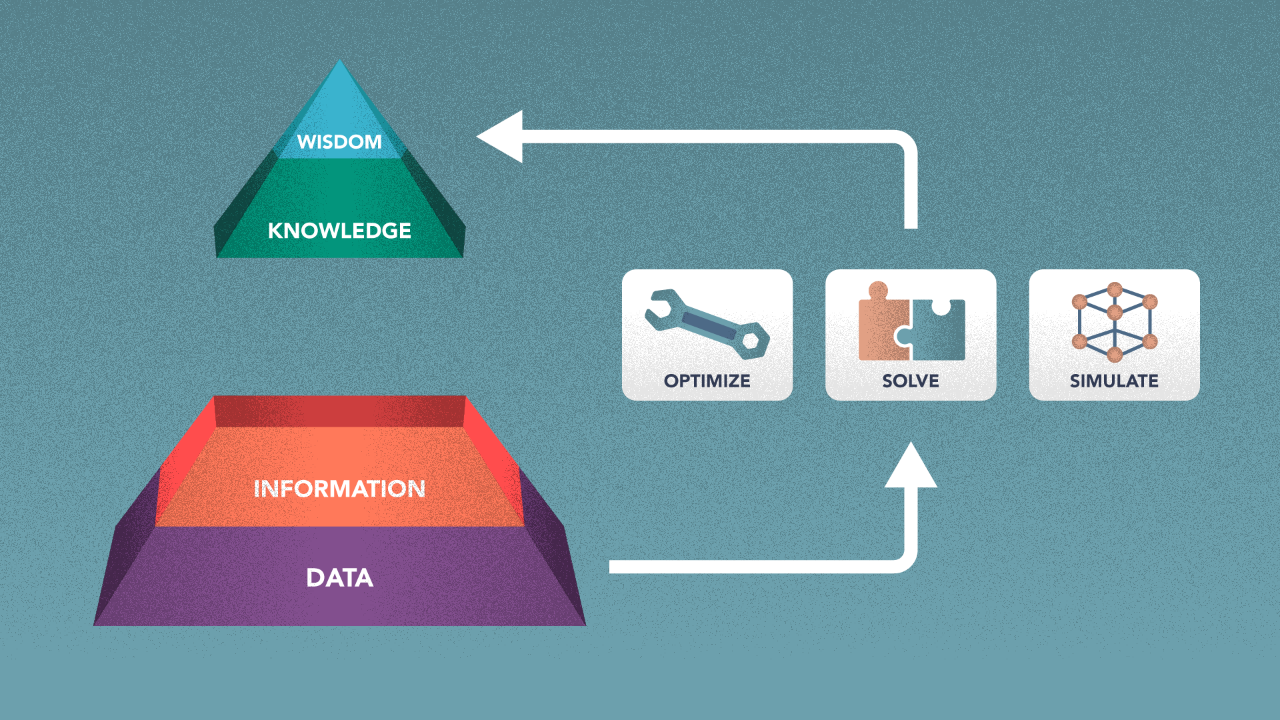
The richer in meaning the input you provide to a hero method, the higher the output in the pyramid. This is as seen in Neurosymbolic models; these have the potential for real breakthroughs in the field. This is assuming of course that you can get them to work well! Using Hero-models, we see the potential in building systems that are wise, falling under the realm of wisdom-management. Ultimately, our goal is Artificial Intelligence; in order to get there, Hero Models are key.
Ontologies, expert systems, and case-based reasoners, need mechanisms that allow us to exploit their underlying knowledge representation. Simple operations involve graph navigation and retrieval while anything sophisticated will require implementation of logical reasoning constructs.
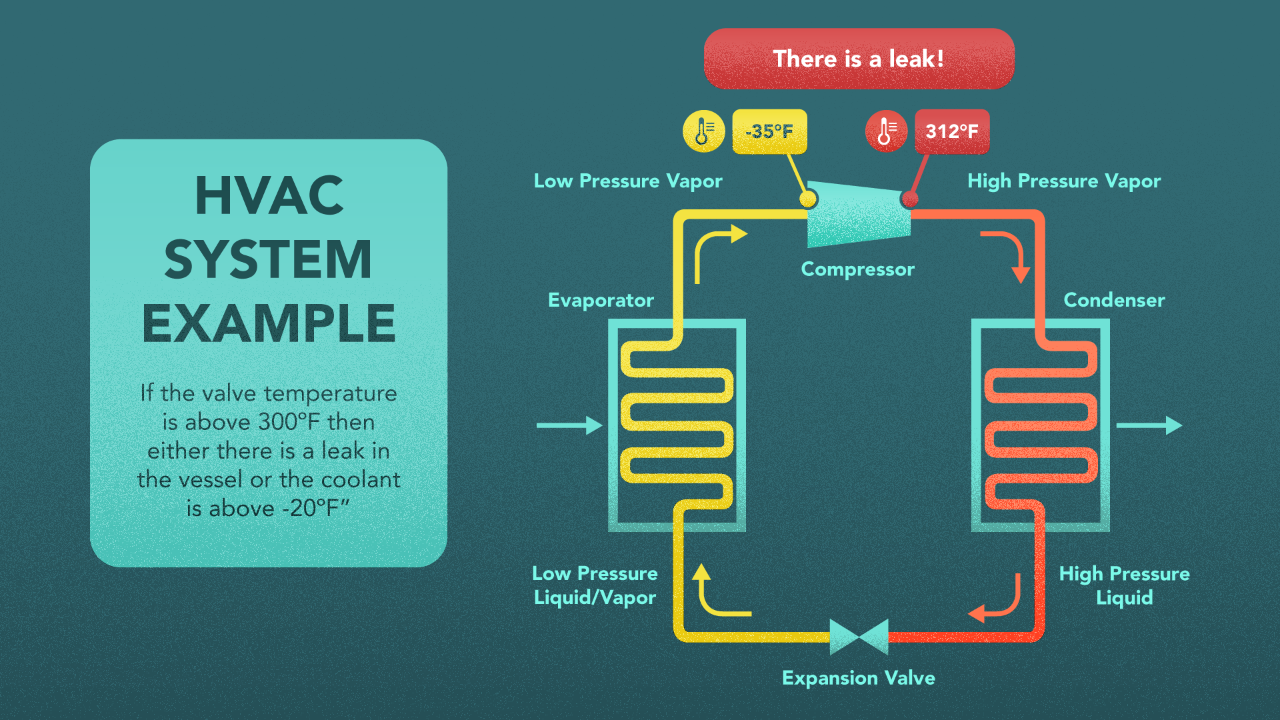
For instance, say we are able to model rules in an HVAC system such as “If the valve temperature is above 300ºF then either there is a leak in the vessel or the coolant is above -20ºF”. Further, the sensors provide readings that say “valve temperature = 312ºF” and “coolant temperature = -35ºF”. Based on this, we need an automatic mechanism that can put these two together and infer that “there is a leak in the containment vessel”.
- - -
At Kado, we like to connect the dots between the different types of Knowledge Representation. Here are some closing notes.
One way to automatically infer from rules and facts is the use of logic programming languages. Many publicly available ontology and expert systems also have reasoners built in as standard features. Also rule-based production systems or any other programmatic method may be used to query graphs/networks and ontologies.
This is how we see the world
Machine Learning is King, but of narrow territory. Hero Methods do things that ML cannot. Taken together, not only do they help solve complex problems, they also lay the doorway to AI.
Get in touch
-
Milton, ON L9T 6T2, Canada
-
help@kado.ai
-
+1 416 619 0517
Copyright © 2026
Super!
An email is on it's way.
Super!
An email is on it's way.
Created with
