
Remodelling a learning problem
Oct 14, 2022 | Jagannath Rajagopal | 3 min read
What are some other ways in which a learning problem may be modelled? Image, video and speech recognition traditionally involved the use of hand-built filters to parse out certain types of patterns from the data.
The Sobel operator is a popular filter for edge detection in images while the Hough Transform is one used for circle detection.
However, given the complexity of the problem space and richness of patterns, an approach that requires hand-tailoring filters does not scale; and furthermore results in inaccurate models.
With the advent of deep learning, the problem of scaling was overcome; we now have highly accurate models. Deep learning methods are now state-of-the-art when it comes to image recognition.

If your images do not have labels, one of the traditional methods for Image Segmentation is unsupervised learning — where one does the segmenting by training a model to recognize parts of an image that are similar to one another.
I’ve created a LOT of resources on this topic. Here’s my course on Design Thinking for Hero Methods. Here’s my YouTube channel with previews of course videos. Here’s my website; navigate through the courses to find free previews & pdfs.
- - -
What is another way to re-cast this? In the case of Image segmentation, we can think of it as an optimization problem. Instead of training across a large batch of images, you can optimize them individually — image by image. For any image, you can choose and iterate between a variety of segment configurations, and choose the one where the difference between pixel intensities is the highest.

Why is this relevant? Learning problems are trained by minimizing the error between predictions and actual values across a large data set. In other words, they are trained by optimization methods that are stochastic.
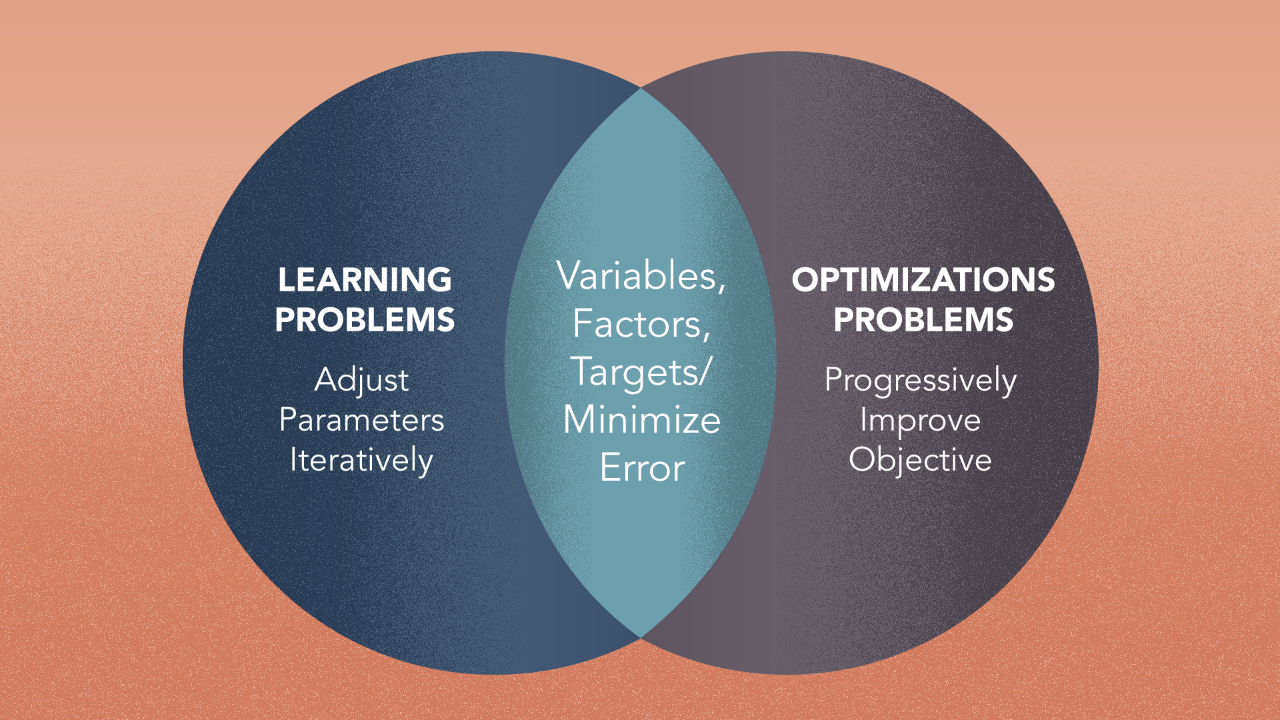
But why is that? Learning and optimization problems have many things in common structurally.
They both involve data spaces with a variety of variables — factors or targets. In learning, parameters are adjusted iteratively over the course of training so that error is minimized progressively.
In optimization, the solution is arrived at iteratively over the course of training so that the objective is improved progressively.
A key deciding factor to consider — if you optimize an image and start over for the next one, you are not generalizing anything.
By this we mean, knowledge gained about image inter-relationships is lost between images.
This in essence is the crux of learning methods. The idea is to invest time and computation up front, so that downstream effort in inference is reduced.
However, what if there is no need to generalize? If the problem scope is limited just to a particular set of images, optimization may be more effective. Alternately, for some problems, images may not have much in common, or have multiple key patterns that only occur once or a few times. In such scenarios, learning may be neither enough nor necessary.

The same discussion largely holds true if this is recast as a search problem. It could work one at a time, but there is no generalization built in.
At Kado, we are interested in combining pieces in an architecture. A key question then would be interchangeability. By asking the question about whether one method can be replaced by another — especially when they belong to different families, we learn something about why a particular method is right for that problem slice. If we find that no one method in particular holds an edge, the door is now open to combine them together in an ensemble, thus increasing the robustness of results.
This is how we see the world
Machine Learning is King, but of narrow territory. Hero Methods do things that ML cannot. Taken together, not only do they help solve complex problems, they also lay the doorway to AI.
Get in touch
-
Milton, ON L9T 6T2, Canada
-
help@kado.ai
-
+1 416 619 0517
Copyright © 2026
Super!
An email is on it's way.
Super!
An email is on it's way.
Created with
