
Think only data-driven problems matter? Think again!
Oct 13, 2022 | Jagannath Rajagopal | 8 min read
What is a data driven problem? A problem is considered to be data-driven if data takes foremost precedence in arriving at the solution. Examples of data driven problems include image recognition and natural language processing. A specific example is Apple’s FaceID which uses face recognition to unlock a device.
How does a model learn about its world? For a driverless car, it would be through its sensors — camera, radar, lidar, microphone, gps etc. The sensors capture data while on the road. Historical data can be used to build a model of the world, which is in turn used in driving. So, the problem is defined by its input. Data acts as the enabler as well as forms the boundary in problem definition and scope.

Next up, what are principle driven problems? A problem is “principle-driven” if algorithms, methods and techniques take precedence over data and expert knowledge. For example, a financial market simulation is principle driven because it is guided by cause and effect relationships and model principles. Generative design systems are also principle driven.

Finally, what are knowledge or experience driven problems? A problem is knowledge-driven if the primary driver is formal or expert knowledge. There can be quite a variety of examples of knowledge/experience based problems: everything from recipes that are “to taste” to marketing/sales problems where things are known from past experience. These require knowledge in addition to a grasp of the principles involved in order to be solved correctly.

Now that we have some of the verbiage out of the way, it’s time for an example.
- - -
Let’s think about a model developed for autonomous driving. How would this model learn about its world? To start, a driverless car must have several sensors feeding the model data: there’s cameras, and radar, and lidar, and microphones, throw in computer vision, definitely some sonar, and GPS — and — likely a bunch of other types of sensors.

But maybe we got ahead of ourselves. Every autonomous driving model must have its baseline data. What are the size, shape, weight, and dimensions of the vehicle? How many horsepower does the engine have? How do those horses affect acceleration of the vehicle? What’s the braking distance at different speeds?In this regard, principles of physics and dynamics come into play.
What if the surface you’re braking on is slick from rain? More physics/dynamics. Does the model understand the concept of rain ? How does it know it’s raining? Is anyone in the cabin? Do they need to see clearly? Maybe the model should turn these wipers on and defog the windshield…What speed should be used for the wipers based on the rain?

What’s this thing approaching? How should the car and its passengers interact with this thing approaching? Are there general rules that should be followed for interacting with other objects? But wait wait wait, are we reinventing the wheel here…?
While some considerations of how the model should behave can be based on general preset rules and raw data input, in order for an autonomous vehicle to drive properly — and without error, it’s helpful to also have expert knowledge of what might occur in certain situations, especially when considering what a human (and often erratic) driver of another vehicle is likely to do.
- - -
Let’s take a sec to think about a model built for marketing analysis. Let’s say that the execs at the Amazing Beverage Company (animation of a delicious ABC cartoon beverage onscreen) want to analyze the performance of their different flavours regionally.
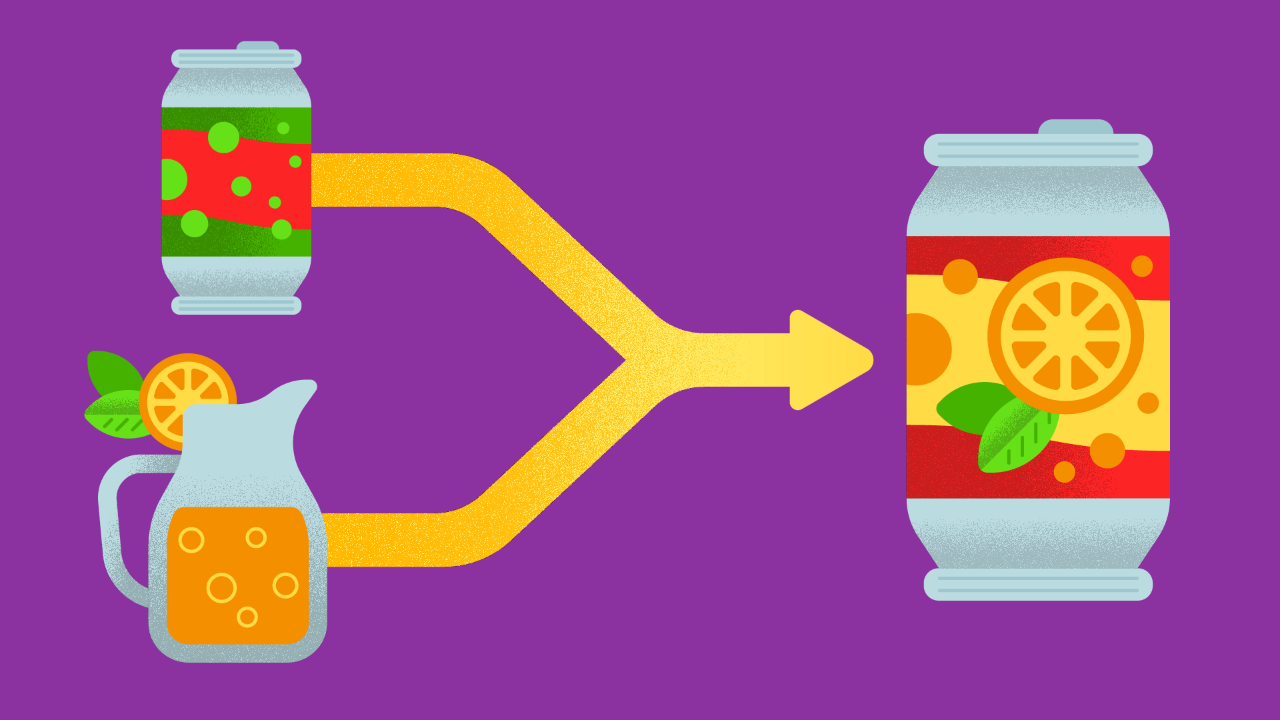
Sure, you could just feed the model the sales numbers — and that’d tell you that ABC Tajin Infused Watermelon Lemonade is a top seller in these regions. And it’d tell you when these beverages sold the most, how many units, the sizes that are most popular, etc. But what if you NEED to know — why? Why does that delicious mouth watering ABC Tajin Infused Watermelon Lemonade sell so well in the summer in Los Angeles, as opposed to say Southwestern Kentucky? Maybe it’s the demographic of the people in the area, or the foods that are complimentary to the beverages, or the locations where your beverages are sold — say out of corner stores or restaurants versus out of supermarkets. Or maybe they just like their tea a little sweeter.
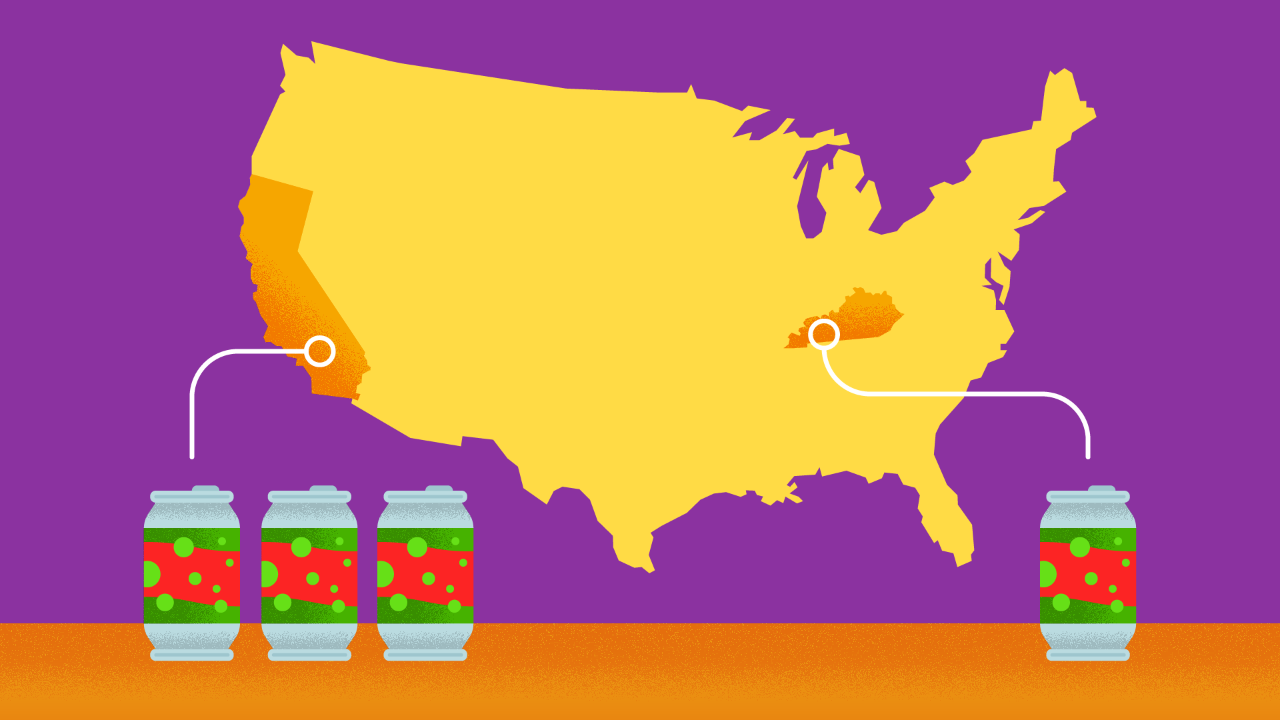
That’s where expert knowledge and experience would come into play. Models sometimes need problem analysis from the experts to make them run properly. So NOW you can shill a lot more ABC Tajin Infused Watermelon Lemonade in Southwestern Kentucky. Especially if it’s been mixed with a little Sweet Tea.
I’ve created a LOT of resources on this topic. Here’s my course on Design Thinking for Hero Methods. Here’s my YouTube channel with previews of course videos. Here’s my website; navigate through the courses to find free previews & pdfs.
- - -
Wanna do one more? Let’s do one more.
Consider an airplane wing, there are all different types — from fighter jets, to passenger airliners, to single engine Cessnas. What’s consistent when designing the wings of a plane, is that certain designs fly and others — won’t. For domains like engineering design, principles form the primary input when building models. Principles include well-defined methods and procedures used to calculate cause and effect relationships.

- - -
Of course, these metaphors are not limited to driverless cars, marketing and/or engineering design.
Did you know that there are ways to model intuition? A model can infer certain relationships between things based on a little bit of experience or expert knowledge. Let’s say we want the model to determine relationships between a group of people who are connected on a social networking platform. And for those of you thinking “there are massive privacy concerns” — let’s all have a collective sigh of relief here — we’ll say this model is only used to make each user’s experience more intuitive and improve the UX, but it isn’t available to other potentially snoopy humans or companies. Doesn’t that put you at ease? Maybe not — ahhhh okay, let’s get on with it.

The model would have access to general data, i.e. photos of users, users list of “friends”, and a record that person X has contacted person Y. The model would easily be able to figure out who each user is connected to and who is friends with who.
But here’s the real question…who is who’s best friend?
I mean Bo and Katie are close…but are they close close? Oh my God, are they BESTIES!? The degree of closeness would be something that the model wouldn’t be able to discern by relational understanding alone.

A bit of human knowledge — almost like a hint to the model in this case — is necessary to give an understanding of the degree of closeness. A human — a human snoop, let’s be honest — would know that in order to infer a degree of closeness you should check and see if these two people are pictured together- — AND if they’re close together in pictures — AND to check not just how frequently they interact with each other but also WHEN they interact with each other.

Here’s a hint to your model: Do they hang on the weekends? Wait, they posted a picture at the Bungalow having drinks???!! Oh my goodness — why wasn’t I invited? But I digress. Expert knowledge and human insight into relationships between factors can help the model infer things that it would not on its own.
If the model wants to determine whether these two people are related through work, the system architect may help by adding some knowledge. For example: do these people contact each other at times that people normally designate for work? So, 9am-5pm M-F. Do they communicate solely via email? Are the communication channels that they use attached to company domains? Do they contact each other on the weekends or after hours frequently? Are several of their connections also people who work at the same company? All of these factors could help the model arrive at an understanding of what type of relationship these two people have.
If we’re not sure but have a good feeling about something, that can be modelled also. Fuzzy logic & Probabilistic reasoning can used to describe uncertainty and approximate reasoning.

Let’s go back to those friends who went out to the Bungalow without me. Hurtful!!! The model may gather some understanding of the relationship between Bo and Katie, BUT it may not be sure about the full context of their relationship. How do they know each other? Do they work together? Are they connected through a much cooler third person who is a better friend to both of them? Probably. Is there a familial relationship? The answer to all of these questions is likely…maybe.

The model would use probability in this case to determine a degree of uncertainty. It’s 90% sure they are friends, 80% percent sure they are close friends, 95% sure they aren’t family. You get it, let’s move on.
- - -
In some cases, there may already exist models or simulations for part of the problem. The challenge is then to calibrate that model or to find the best configuration for a particular situation or use. Given a configuration, it is possible to simulate its behaviour, but you still do not know which is the optimal configuration that maximizes the performance.
At Kado, our job is to ponder about topics such as this. When you’re designing a model, consider if vital knowledge might be lost by resorting to a purely data driven approach. Alternately, principles may outweigh expert knowledge or data; if so a principle driven approach may be well suited for you.
Don't hesitate!
Design Thinking for Hero Methods!
This is how we see the world
Machine Learning is King, but of narrow territory. Hero Methods do things that ML cannot. Taken together, not only do they help solve complex problems, they also lay the doorway to AI.
Get in touch
-
Milton, ON L9T 6T2, Canada
-
help@kado.ai
-
+1 416 619 0517
Copyright © 2026
Super!
An email is on it's way.
Super!
An email is on it's way.
Created with
